


1. 포인터 변수와 &, * 연산자
C 언어에는 포인터라는 특별한 타입의 변수가 존재한다. 많이들 사용하는 int, double, float, char 등 변수와 같이 포인터 변수도 값을 저장하긴 하나, 메모리의 주소 값이라는 특별한 값을 저장한다.
코딩을 하면서 사용하는 모든 데이터들은 메모리에 기록된다. 메모리는 바이트(Byte) 단위로 주소 값이 매겨져 있는데, 변수의 크기만큼 공간을 차지하면 값을 기록하게 된다. 이에 대해서 간단히 설명하면 아래와 같다.

32비트 주소 체계를 기준으로 주소 값은 임의로 설정하였다.
모든 변수를 선언하게 되면 위와 같이 메모리 주소에 정해진 크기만큼 변수에 할당하며, 메모리 공간은 변수의 이름이 붙게 된다. 이렇게 선언된 변수는 포인터 변수에 의해 참조될 수 있다.
int *pa;
int a = 10;
pa = &a;
C
복사
위 구문은 포인터 변수 pa와 int 타입의 a라는 변수를 선언한 것이다. 그리고 제일 아래 구문이 바로 포인터 변수가 일반 변수를 참조하는 것이다. & 연산자는 단항 연산자로써 변수 앞에 &를 붙임으로써 변수의 주소를 의미할 수 있다. 즉, 해당 구문은 a의 주소를 pa에 할당해줘라고 볼 수 있다.
#include <stdio.h>
int main()
{
int *pa;
int a = 10;
pa = &a;
printf("%p\n", pa);
printf("%p\n", &a);
printf("%lu\n", sizeof(pa));
return 0;
}
C
복사
그렇다면 pa라고 하는 변수에는 어떤 값이 있는지 확인해보기 위해 위 코드를 실행하여 pa의 값과 a의 주소 값을 확인해보면 다음과 같은 결과가 나오는 것을 볼 수 있다. (printf의 %p라는 형식 지정자는 주소 값을 출력하기 위한 형식 지정자이다.)
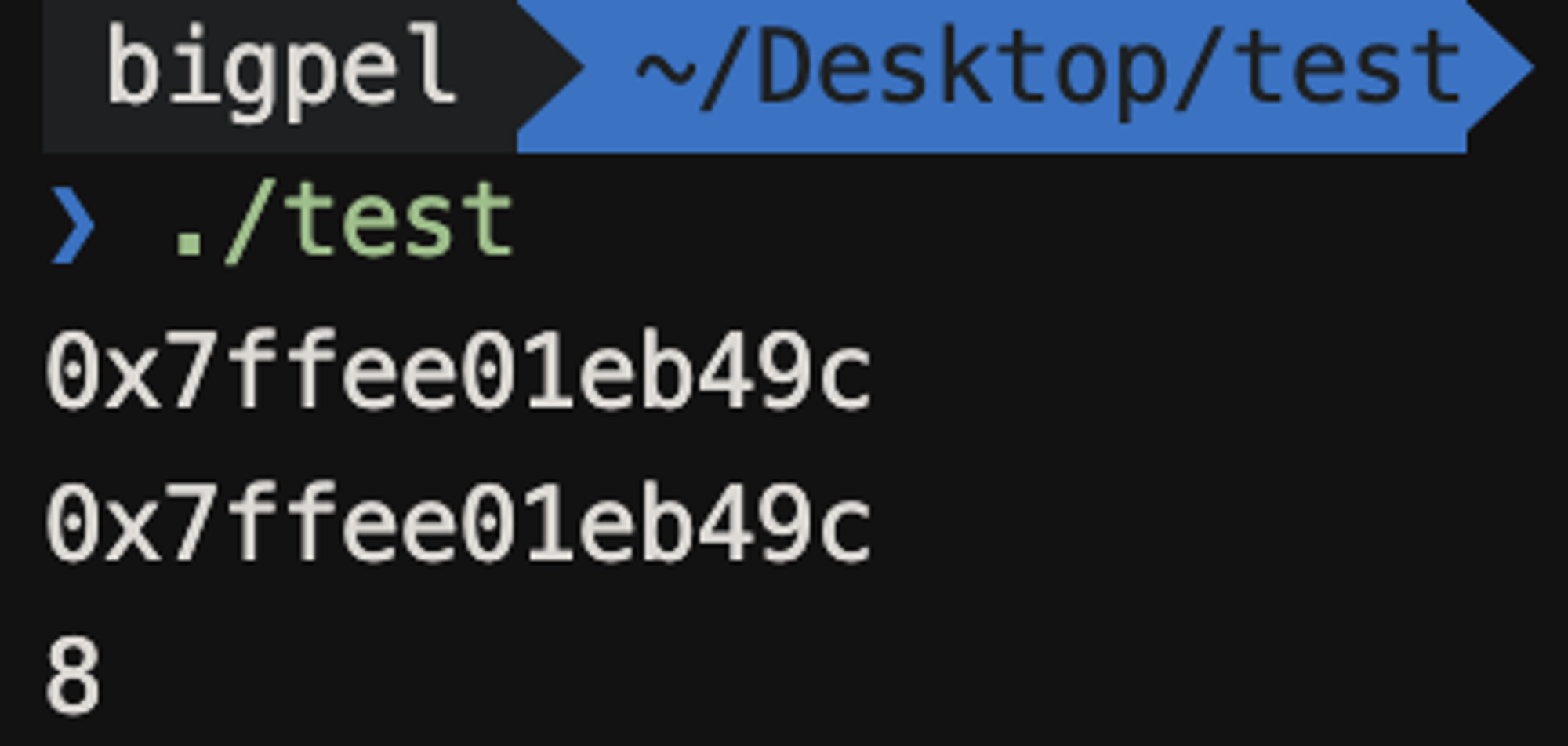
주소 출력 결과 16자리가 안 나오는 것은 출력 과정에서 앞의 0이 생력되어 64비트 주소 체계임에도 16자리가 안 나오는 것이다.
pa가 갖고 있는 값과 a의 주소를 확인 해보니 동일한 값이 나온 것을 볼 수 있다. 따라서 pa라는 포인터 변수가 int 타입의 a라는 변수를 참조한다는 것은 포인터 변수 pa가 변수 a의 주소 값을 갖고 있는 것으로 볼 수 있다. 즉, 포인터 변수는 포인터 변수가 참조하고 있는 변수의 주소를 갖는다는 것이다.
포인터 변수의 크기는 어떻게 될까? 이는 주소 체계를 몇 비트로 이용하는지에 따라서 크기가 달라진다. 만일 주소 체계를 32비트로 사용한다면 포인터 변수의 크기는 32비트 (4바이트)가 되는 것이고, 64비트 주소 체계를 이용하면 포인터 변수의 크기는 64비트 (8바이트)가 되는 것이다. 즉, 위 예시에서는 포인터 변수에 대해 sizeof를 수행했을 때 8바이트가 나온 것을 보아 64비트 주소 체계를 사용하는 것을 짐작할 수 있다. (마찬가지로 자필로 적은 예시는 32비트 주소 체계를 사용하여 예를 들었기 때문에, 해당 상황에서 포인터 변수를 이용하면 4바이트의 크기로 변수가 할당될 것을 짐작할 수 있다.) 절대 포인터 변수가 char * 라고 1바이트, double *라고 8바이트 이런 식이 아니다.
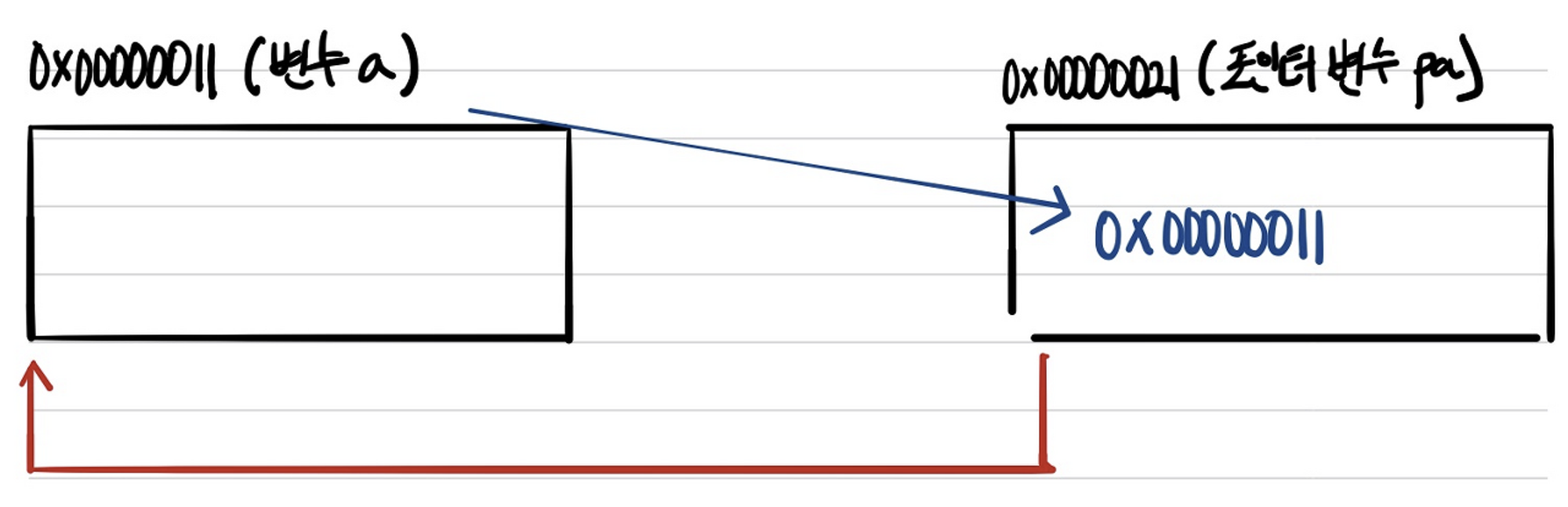
포인터 변수에 대해서 와닿지 않을 테니 위 그림을 통해서 살펴보면, 포인터 변수도 Scope 내에 선언과 동시에 Stack에 포인터 변수의 크기만큼 메모리에 할당된다. 그리고 pa = &a라는 문장을 수행하면서 a라는 주소 값이 pa에 할당되는 것이다. 이렇게 포인터 변수 내에 주소 값이 있는 상태를 포인터 변수가 변수를 참조한다라고 보면 조금 이해가 편할 것이다. 그리고 포인터는 변수이므로 포인터 변수가 참조하는 변수를 변경 시킬 수 있다.
#include <stdio.h>
int main()
{
int *pa;
int a = 10;
int b = 20;
pa = &a;
printf("%p\n", pa);
printf("%p\n", &a);
pa = &b;
printf("%p\n", pa);
printf("%p\n", &b);
return 0;
}
C
복사
위 코드를 수행하게 되면, 포인터 변수 pa에 담기는 주소 값이 a의 주소 값에서 b의 주소 값으로 바뀌는 것을 볼 수 있다.
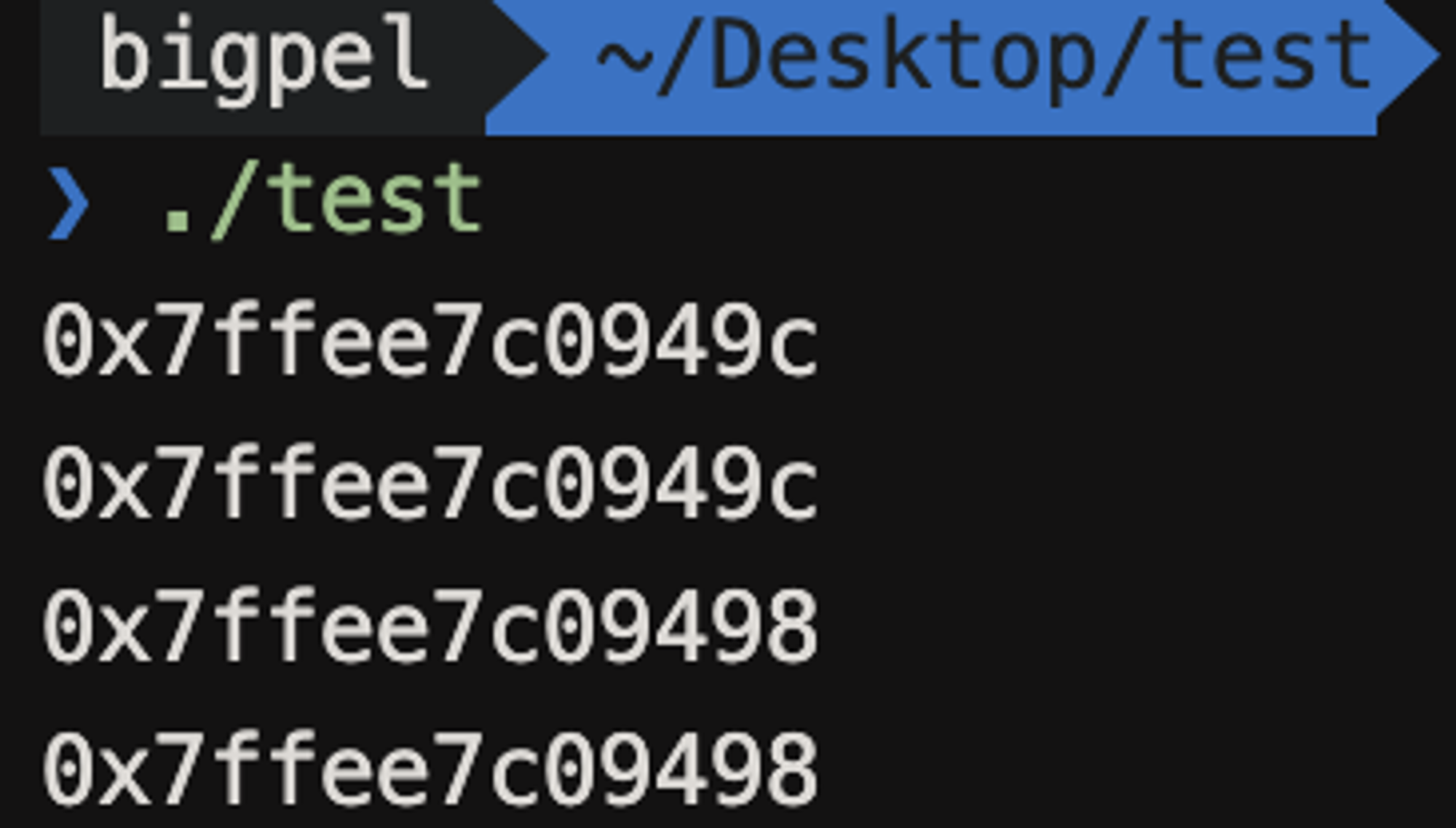
즉, 포인터 변수가 참조하고 있는 변수를 바꿀 수 있다는 말은 Stack에 존재하는 포인터 변수가 갖는 주소 값에 대해서도 변경할 수 있다는 것이다.
포인터 변수가 다른 변수의 주소 값을 갖고 있는 것을 통해 어떤 작업이 가능할까? 포인터 변수가 갖고 있는 주소 값을 역참조하여 데이터에 접근할 수 있다. 말이 조금 어려운데, 만일 위의 예시에서 0x00000011 주소 값의 변수가 int 타입이고 10이라는 값이 저장되어 있다고 생각해보자. 포인터 변수 pa에는 주소 값 0x00000011이 저장되어 있다. 포인터 변수 pa를 이용하여 0x00000011에 대응되는 변수인 a가 갖고 있는 데이터에 접근이 가능하다는 소리이다. 아래 예시를 보자.
#include <stdio.h>
int main()
{
int *pa;
int a = 10;
pa = &a;
printf("%d\n", *pa);
return 0;
}
C
복사
이전 예시와 마찬가지로 포인터 변수 pa는 변수 a의 주소 값을 가지면서, a를 참조하고 있다. 그리고 printf를 통해 *pa를 찍어서 %d 형식 지정자로 어떤 값이 나오나 확인해보았다.
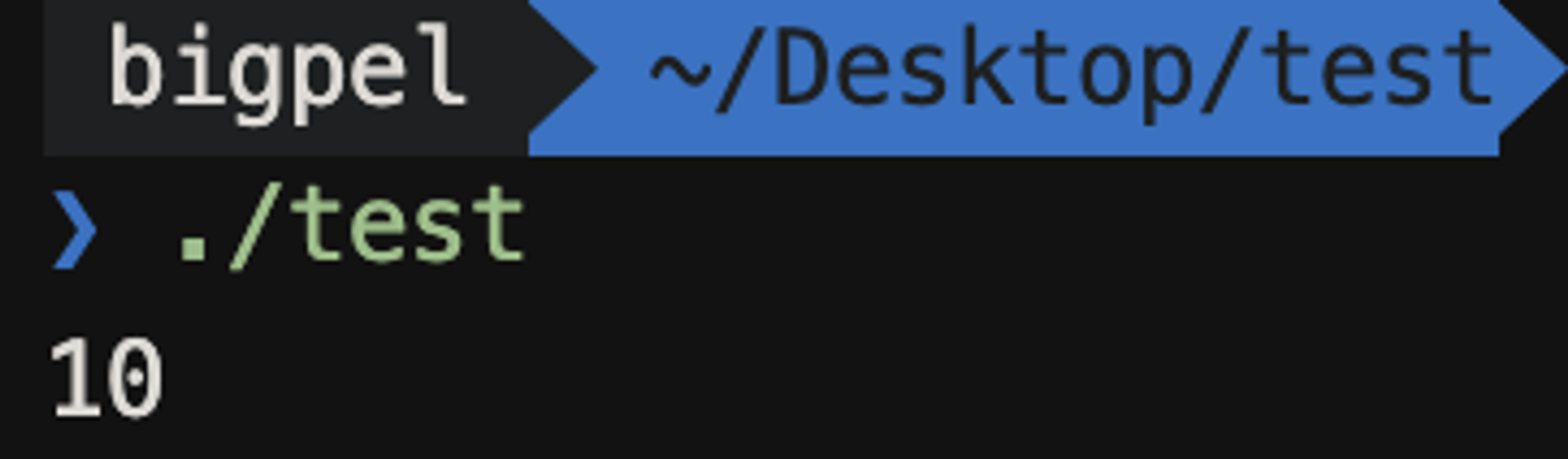
결과는 위와 같이 a에 대입했던 10이라는 값이 나왔다. 포인터 변수에 * 연산자를 붙였더니 a의 값이 나왔다. * 연산자는 이항 연산자로 사용하면 x * y처럼 곱셈 연산으로 처리 되지만, 단항 연산자로 이용할 경우에는 포인터 변수 앞에서 사용될 수 있다. 포인터 변수 앞에 * 연산자가 단항으로 붙게 되면, 포인터 변수가 갖고 있는 주소에 대응되는 변수로 이용하게 된다. 따라서 *pa라고 하면, pa가 참조하고 있는 a라는 변수를 역참조하여 a 변수 자체로 이용해라고 하게 되는 것이다.
선언할 때 사용하는 Asterisk와는 다른 의미이다. 선언할 때 사용된 Asterisk는 포인터 변수임을 명시하기 위한 용도이다.
위와 같이 Asterisk를 이용하면 참조하고 있는 변수의 역참조가 가능하기 때문에 아래와 같은 것도 가능하다.
#include <stdio.h>
int main()
{
int *pa;
int a = 10;
pa = &a;
*pa = 20;
printf("%d\n", *pa);
return 0;
}
C
복사
*pa = 20이라는 구문을 통해 pa가 참조하는 변수를 역참조하여 변수의 값을 20으로 변경할 수 있다. 위 코드의 출력 결과로 a의 값은 20이 나오게 된다.
위에서 읽은 것대로 포인터 변수가 무엇인지 알아보았다. 그리고 2개의 연산자에 대해서 알아보았는데, & 연산자는 단항 연산자로써 변수 앞에 붙었을 때 해당 변수의 주소 값을 나타낼 수 있게 해준다. * 연산자는 단항 연산자로써 포인터 변수 앞에 붙었을 때, 포인터 변수가 참조하는 변수를 역참조하여 변수 자체로써 사용할 수 있게 해준다. &, * 연산자에 대한 이해만 제대로 하고 있다면, 포인터가 헷갈리더라도 차근 차근 이해할 수 있을 것이다.
2. 포인터에 타입이 존재하는 이유
포인터에 대해서 작성한 간단한 코드를 보았을 때, pa라는 포인터 변수를 단순히 Asterisk로 선언한 것이 아니라 int와 함께 덧 붙여서 int *로 선언한 것을 볼 수 있었다. int *라고 해서 포인터 변수의 크기가 4바이트도 아닌데 왜 int 타입을 붙여서 선언하게 되는 것일까? 단순히 Asterisk를 통해서 선언하도록 만들면 되지 않았을까? 그 이유는 포인터 변수 이후에 사용되는 Asterisk에 있다.
* pa;
int a = 10;
pa = &a;
printf("%d", *pa);
C
복사
타입 없이 Asterisk로 포인터 변수를 선언한 다음과 같은 코드가 있다고 해보자. (그리고 동작한다고 가정해보자.) 위 코드를 사용했을 때, printf에서 문제가 있다. 어떤 문제가 있을까?

따라서 위와 같은 문제가 있기 때문에 포인터 변수를 선언할 때, Asterisk 앞에 어떤 타입을 가진 변수의 주소 값을 저장할 지 명시하여 데이터를 가져올 때 몇 바이트를 읽을지 알게 하는 것이다. (int *라고 하면 int 크기만큼 시작 주소부터 4바이트의 데이터를 읽겠다는 것이며, double *라고 하면 double 크기만큼 시작 주소부터 8바이트의 데이터를 읽겠다는 것이다.)
3. 상수 포인터, 포인터 상수, 상수 포인터 상수
말들이 정말 헷갈린다. 나도 처음 배울 때는 매우 헷갈렸던 기억이 나고, 지금도 솔직히 헷갈린다. 하지만 그렇게 어렵게 생각하지 않아도 된다. 말 그대로 받아 들이면 된다.
•
상수 포인터 → 상수 const / 포인터 *ptr
•
포인터 상수 → 포인터 *ptr / 상수 const
•
상수 포인터 상수 → 상수 const / 포인터 *ptr / 상수 const
위 적힌 3가지를 선언해보면 다음과 같다.
int a = 10;
int b = 20;
const int *ptr1 = &a; // 상수 포인터 (상수를 참조하는 포인터)
int* const ptr2 = &a; // 포인터 상수 (포인터를 상수화)
const int* const ptr3 = &a; // 상수 포인터 상수 (상수를 참조하는 상수화된 포인터)
C
복사
세 구문의 어떤 차이가 있을지 살펴보자.
1) cosnt int *ptr1 = &a;
위 구문은 주석에 적은 것처럼 ptr1이 참조하는 변수를 상수로 인식한다. 즉, int a = 10으로 선언된 변수를 상수로 인식하기 때문에 값을 바꾸는 것이 허용되지 않는다.
*ptr1 = 30; // 오류
ptr1 = &b; // 허용
C
복사
즉, 위와 같이 수행 했을 때 첫 번째 라인은 상수 값으로 인식하는 a 값을 바꾸는 행위이므로 오류가 발생한다. 하지만 포인터 변수가 참조하는 변수를 상수로 인식하는 것 뿐이고 포인터 변수 자체는 여전히 변수이기 때문에 포인터 변수가 참조하는 변수에 대해서는 변경하여도 문제 되지 않는다. 따라서 두 번째 라인에 대해서는 허용된다.
2) int* const ptr2 = &a;
위 구문은 주석에 적은 것처럼 포인터가 상수화 된 것이다. 즉, ptr2가 상수라는 소리이다.
*ptr2 = 40; // 허용
ptr2 = &b; // 오류
C
복사
따라서 상수 포인터에서의 예시를 그대로 수행하면 반대의 결과가 나온다. 포인터 상수는 말 그대로 포인터가 상수므로 포인터가 참조하는 주소 값에 대해서는 변경할 수 없다. 하지만 ptr2는 a를 참조하고 있는데 a 자체는 상수가 아니라 변수이므로 Asterisk를 통해 역참조하여 a 값은 변경할 수 있다.
3) const int* const ptr3 = &a;
상수 포인터와 포인터 상수에 대해 잘 이해했다면, 위 구문은 간단할 것이다. 예상 한대로 포인터가 갖고 있는 주소 값에 대해서도 변경할 수 없으며, 포인터가 참조하는 변수의 값 자체도 변경할 수 없게 된다.
4) 고찰
총 3가지 포인터를 이용한 상수들을 살펴보았는데, 이렇게 const를 붙여서 사용하는 이유는 무엇일까? 여러 이유들이 있겠지만 가장 큰 이유는 프로그래머의 실수로 인한 예기치 못한 오류를 방지하기 위해서라고 생각한다.
코딩을 하다보면 바뀌지 말아야 하는 값이 있는데 간혹 이 값을 바꿔버리면서 예상했던 결과와 다르게 나오는 경우가 허다하다. 그리고 오랜 시간을 들여 확인을 해보면, 값을 그대로 유지해야 하는데 그 값이 바뀌어서 발생한 것이라고 깨닫게 되는 경우가 많다. 이런 오류는 문법적인 오류가 아니기 때문에 컴파일러에서는 아무 문제가 없다고 생각하고 오류를 내지 않기 때문에 운이 나쁘면 굉장히 오랜 시간 뒤에야 그 원인을 찾을 수도 있다. const 키워드를 이용하게 되면 애초에 값 자체가 바뀔 일이 없기 때문에 이런 문제들을 예방할 수 있다. 귀찮더라도 const 키워드를 붙여 이용하다가, 값을 꼭 바꾸면서 이용해야할 때 const 키워드를 해제하는 식으로 코딩하는 습관을 들이는 것이 좋다.
내가 아는 const 키워드의 이점은 하나 더 있는데, 이는 C 언어에서의 이점은 아니다. Flutter를 사용할 때 렌더링에 이용되는 Widget들을 const를 붙여서 사용할 수 있다면 const를 꼭 이용하는 것이 좋다. Flutter에서는 setState 함수를 통해 State를 변경시킬 때, 렌더링에 필요한 Widget들을 모두 Rebuild하게 된다. 이 때, const 키워드가 붙은 Widget들은 항상 그 값을 유지하며 바뀌지 않기 때문에 Rebuild를 해도 같은 값이 유지된다. 즉, const 키워드가 붙은 Widget들은 값이 항상 일정하기 때문에 Rebuild를 할 필요가 없어지는 것이고, 자원을 들여서 해당 Widget을 다시 렌더링 할 필요가 사라지는 것이다. 이는 곧 어플 구동에 성능 향상으로 이어질 수 있는 것이다.
분명 다른 언어에서도 const를 사용했을 때 이점이 분명 있을 것이기 때문에, 이처럼 const를 붙여서 코딩하는 습관을 두는 것이 좋다고 생각한다.
4. 포인터의 사칙연산
포인터에서의 사칙연산은 다른 변수들의 사칙연산과 달리 조금 특별한 점이 있다.
•
포인터 변수에 대해 곱셈과 나눗셈의 이용이 불가능하다. (포인터 변수 간에도 불가능하고, 수와 포인터 변수 사이에도 불가능하다.)
•
포인터 변수 간의 덧셈 연산은 불가능하지만, 수와 포인터 변수 사이 덧셈 연산은 가능하다.
•
포인터 변수 간의 뺄셈 연산은 가능하다.
이 3가지 중에서 수와 포인터 사이 덧셈과 포인터 변수 간의 뺄셈에 대해서 확인해보자.
1) 수와 포인터 변수 사이 덧셈
#include <stdio.h>
int main()
{
int a = 10;
int *pa = &a;
printf("%p\n", pa);
printf("%p\n", pa + 1);
printf("%p\n", pa + 2);
return 0;
}
C
복사
printf를 3번 이용하여 주소 값을 출력해보았다. 주소 출력의 인자로는 포인터 변수에 1씩 증가한 것들인데, 그 결과가 어떻게 나올까?
포인터 변수에 1씩 더했더니 실제 주소 값은 4씩 증가한 것을 볼 수 있다. 이는 포인터 변수 pa가 int *타입으로 int 타입의 변수를 참조하기 때문이다. 포인터 변수 pa가 참조하는 것은 변수 a이고, 변수 a는 int 타입으로 4바이트의 크기이고 이는 포인터 변수 선언 시 int *로 명시 했기 때문에 포인터 변수 pa의 Coverage는 포인터 변수가 갖고 있는 주소 값을 포함하여 4개까지이다. 따라서 포인터 변수를 1 증가시키면 int 타입의 4바이트 Coverage 바로 직후인 4가 증가된 주소가 출력되는 것이다.
그렇다면 double 타입의 변수를 double *로 가리켰을 때 해당 포인터를 1 증가시키면 8씩 증가하게 될까?
#include <stdio.h>
int main()
{
double a = 10.0;
double *pa = &a;
printf("%p\n", pa);
printf("%p\n", pa + 1);
printf("%p\n", pa + 2);
return 0;
}
C
복사
위 코드를 실행해보면 포인터 변수가 1씩 증가 했을 때 주소는 8씩 증가하는 것을 볼 수 있다. 위에서 언급한 것처럼 double 변수는 8바이트고, double *의 Coverage는 double 크기만큼인 8바이트를 가지므로 주소는 8씩 증가하게 되는 것이다.
이런 수와 포인터 변수 사이 덧셈이 가능하듯이 수와 포인터 사이의 뺄셈도 같은 원리로 가능하다.
2) 포인터 변수 간의 뺄셈
포인터 변수 간의 뺄셈은 서로 동일한 타입에 대해서만 연산이 가능하다.
#include <stdio.h>
int main()
{
int a = 10;
int b = 20;
double c = 30.0;
int *pa1 = &a;
int *pa2 = &b;
double *pa3 = &c;
printf("%p\n", pa1);
printf("%p\n", pa2);
printf("%p\n", pa3);
printf("%ld\n", pa2 - pa1);
printf("%ld\n", pa3 - pa1);
return 0;
}
C
복사
위처럼 int *타입을 갖는 pa2와 pa1의 포인터 변수 간 뺄셈 연산은 가능하지만, double *타입인 pa3와 pa1 사이 뺄셈 연산은 오류를 발생시킨다.
그렇다면 int *타입을 갖는 두 포인터 변수 pa2에서 pa1을 빼게 되면 어떤 값이 나올까?
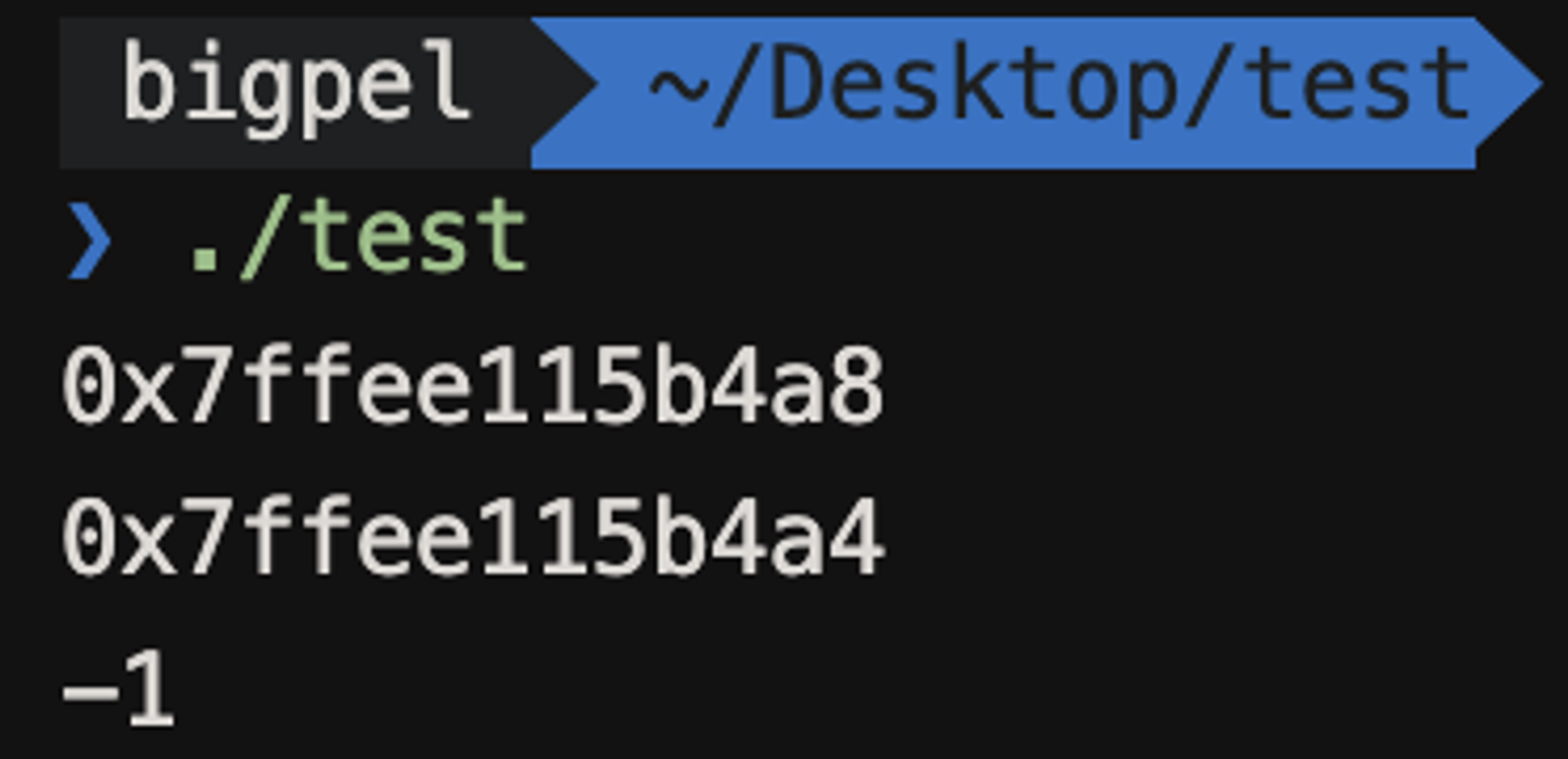
다음과 같이 -1이라는 값이 나온다. 이는 Stack의 구조를 이해하면 조금 받아들이기 쉬운데, 지역 변수에 대해서 Stack의 메모리를 할당하게 되면 높은 주소 값에서부터 낮은 주소 값 방향으로 할당된다. a가 먼저 선언되었고 그 다음 b가 선언되었기 때문에 a가 더 큰 값을 갖게 되는 것이고, a는 int 타입이기 때문에 4바이트 크기만큼의 차이를 갖고 b를 할당하게 된다. 4바이트만큼의 주소 값 차이를 보이기 때문에 int *타입의 포인터 변수 간의 차이는 1이 된다. 여기서 큰 값에서 작은 값을 뺀 것이 아닌, 작은 값에서 큰 값을 뺐기 떄문에 연산 결과는 -1이 되는 것이다.
int *타입의 Coverage는 int 타입의 크기만큼인 4바이트므로 4바이트의 차이는 포인터 변수에게 있어서 1의 차이인 것이다.
5. [] 연산자
우리는 배열을 사용할 때, 대괄호를 이용해서 배열의 인덱스에 해당하는 값에 접근하게 된다. 이 대괄호가 갖는 의미가 따로 있을까?
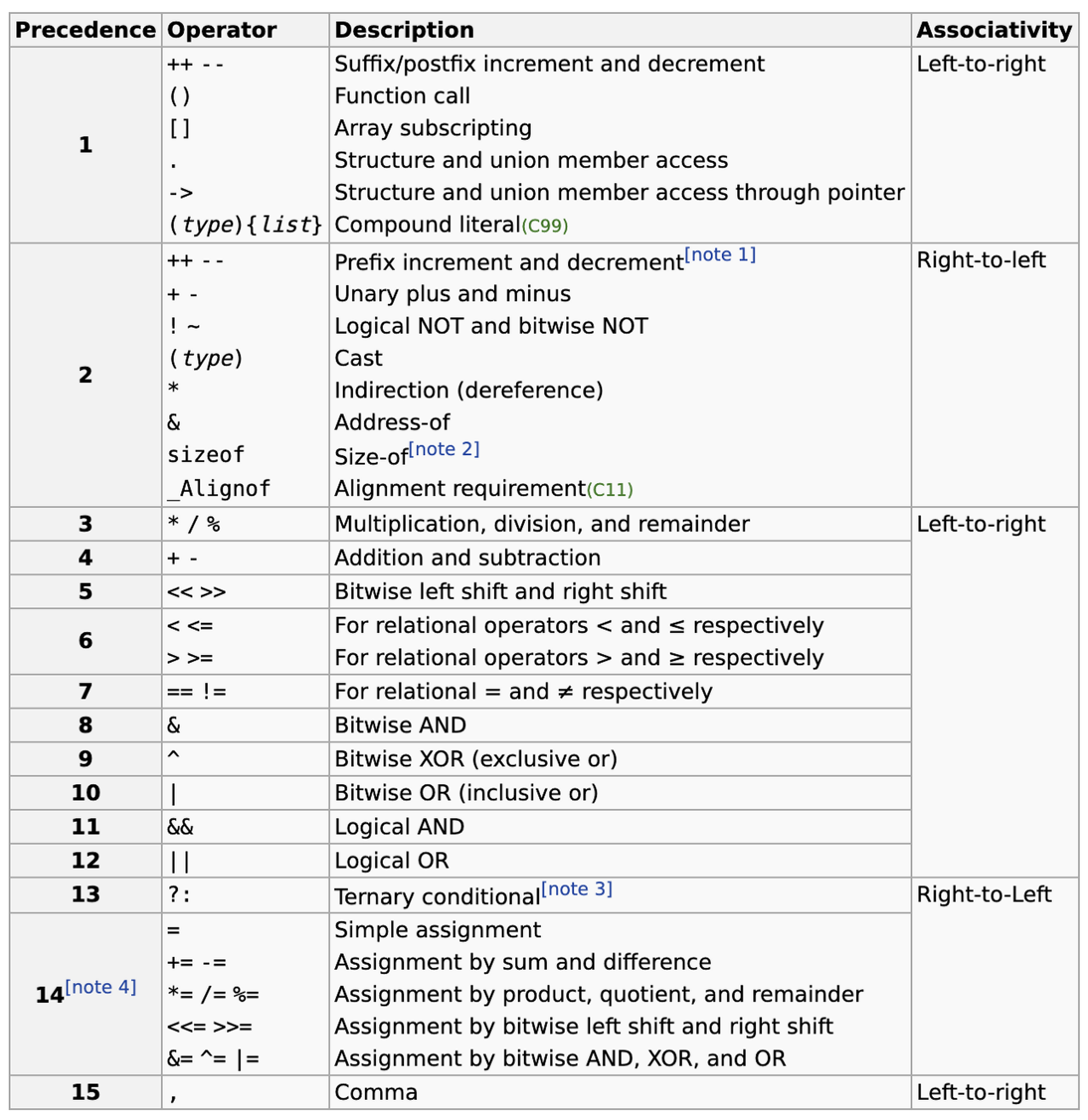
우선 연산자 표에 대괄호가 있는 것도 놀랍지만 우선 순위를 보면, 가장 먼저 처리된다고 볼 수 있는 중괄호 기호 다음으로 빠른 것을 볼 수 있다
int arr[100] = {0};
printf("%d", arr[3]);
C
복사
위와 같은 코드가 있다면, printf 안에서는 arr[3]에 대해 대괄호 연산자가 가장 먼저 수행되면서 해당 구문을 수행하게 된다. 그렇다면 대괄호는 배열에 대해서 어떤 연산을 수행하게 되는 것일까?
arr[3]이라고 하는 것은 컴파일 하게 되면 *(arr + 3)과 같이 처리 된다. (배열도 변수 타입의 크기만큼 차이를 두고 메모리를 할당하게 되고, 포인터도 담은 주소 값에 해당하는 변수의 Coverage만큼 증가하게 되기 때문에 서로 동일한 원리이다.) 이런 수와 포인터 변수간의 연산에 대해서는 일반 사칙연산과 동일하기 때문에 덧셈에 대한 교환법칙이 성립하게 된다. arr[3]이 *(arr + 3)으로 치환된다고 했고, 이는 *(3 + arr)과 같은데 그러면 *(3 + arr)과 동일한 3[arr]도 이용이 가능할까?
#include <stdio.h>
int main()
{
int arr[5] = {1, 2, 3, 4, 5};
printf("%d\n", arr[3]);
printf("%d\n", *(arr + 3));
printf("%d\n", *(3 + arr));
printf("%d\n", 3 [arr]);
return 0;
}
C
복사
printf를 통해서 arr[3], *(arr + 3), *(3 + arr), 3[arr]을 출력해보면 놀랍게도 모두 다 4라는 동일한 값으로 나오고, 3[arr]이라는 표현식도 사용할 수 있는 것을 확인할 수 있다. (사실 3[arr]과 같은 표현은 그 의미를 해석하기에도 이상하게 해석되기도 하며, 가독성이 떨어지기 때문에 이용하지 않는다.)
배열은 포인터 변수에 대한 연산으로 바뀌어 이용된다고도 했고, 배열의 인덱스 증가와 포인터 값의 증가와 많은 연관성이 있어 보인다. 실제로 배열의 시작 주소를 포인터로 가리켜 포인터 값을 증가시켜도 배열의 인덱스에 해당하는 값에 대해서 접근할 수 있었다. 그렇다면 배열의 이름은 포인터일까? 배열은 포인터인지 고민을 해보자.
6. 배열은 포인터인가?
대괄호 연산자를 통해서 배열은 포인터인지 고민하게 되었다. 배열은 포인터인가? 결론부터 말하자면, 배열은 배열이고 포인터는 포인터이다. 서로 별개의 것이라는 말이다. 그럼 배열과 포인터가 서로 다르다면, 어째서 배열의 이름을 출력해보면 포인터처럼 주소 값이 출력되며, 어떻게 배열을 포인터처럼 이용하면서 연산도 가능한 것일까? 배열의 이름부터 살펴보자.
#include <stdio.h>
int main()
{
int arr[5] = {1, 2, 3, 4, 5};
int *parr = arr;
printf("%p\n", &arr[0]);
printf("%p\n", parr);
printf("%p\n", &arr);
printf("%p\n", arr);
return 0;
}
C
복사
배열의 이름에 숨겨진 비밀을 알아보기 위해 포인터 변수 parr로 &arr이 아니라 배열의 이름인 arr을 직접 참조시켜 보았다. 그리고 이를 arr의 시작 원소인 0번째 인덱스를 가진 원소의 주소 값과 비교했다. 배열 이름 arr을 직접 가리킨 결과와 arr의 첫 원소의 주소 값은 동일한 결과가 나왔다.

결과 값이 모두 같다!
1) 배열을 포인터처럼 사용할 수 있는 이유
나는 변수의 이름에 Ampersand를 붙여서 주소 값을 포인터 변수에 할당하는 방법과 달리, 배열 이름에 Ampersand를 붙이지 않고 포인터 변수에 할당 했는데도 주소 값이 찍혔다. 심지어는 첫 번째 원소의 주소 값과 일치하다고 하니, 배열 이름에 Ampersand를 붙이지 않고 직접 할당된 포인터 변수는 배열의 첫 원소를 참조하고 있었던 것이다.
그러면 배열 이름에 Ampersand를 붙여서 주소 값을 출력해보면 어떤 결과가 나올까? 놀랍게도 배열의 이름으로 주소 값을 뽑은 것과 배열의 이름에 Ampersand를 붙여서 주소 값을 뽑은 것 조차 같은 결과가 나왔다. 굉장히 놀랍지 않은가? 나는 이 개념이 굉장히 헷갈렸던 기억이 난다. 왜 위와 같은 것들이 가능한 것일까?
배열 이름을 포인터처럼 사용할 수 있는 것은 포인터로 암시적 형 변환(Implicit Type Conversion) 해주기 때문에 포인터처럼 쓸 수 있는 것이다. 배열 이름을 암시적 형 변환 없이 배열 그 자체로써 인식하는 경우는 두 케이스 밖에 없다. 첫 째는 sizeof의 인자로 배열을 줄 때이고, 둘 째는 단항 연산자 &를 배열에 사용할 때이다.
2) 배열을 배열 그 자체로써 인식하는 경우
sizeof
포인터에 대해서 sizeof를 이용하여 그 크기를 출력하면, 주소 체계의 비트만큼의 크기가 나온다. (64비트 이용 시에 8바이트, 32비트 이용 시에 4바이트와 같이 말이다.) 하지만 배열 이름에 대해서 sizeof를 이용하여 그 크기를 출력하면, 배열이 갖는 원소들의 크기의 합이 나온다. 예를 들면 int 타입의 배열의 원소로 10개가 있다면 해당 배열의 크기는 40이 된다. 즉, 배열 이름이 포인터라면 배열 이름으로 크기를 확인했을 때 그 크기가 포인터처럼 나와야 하는데 그렇지 않다는 것이다.
&
위의 예시에서 제시한 것처럼 arr에 대해서 %p 형식자로 주소를 출력했을 때와 arr에 Ampersand를 붙여서 %p 형식 지정자로 주소를 출력했을 때 동일한 주소 값이 나온 것도 단항 연산자 &에 대해서는 배열 이름을 배열 그 자체로 인식하기 때문이다. 따라서 arr로 배열 이름을 직접 명시했을 때는 포인터로의 암시적 형 변환이 일어나기 때문에 주소 값이 찍히며, arr에 Ampersand를 붙이게 되면 포인터가 아닌 배열로 인식하면서 배열의 주소를 나타내므로 두 값이 동일하게 나타나는 것이다.
3) 암시적 형 변환의 기원
위의 두 케이스를 제외하고서 배열 이름을 사용했을 때 포인터로 암시적 형 변환을 해준다는 것을 잘 생각해보면 형 변환을 해주는 것이기 때문에 배열 이름이 갖는 주소 값을 메모리에 저장하지 않는 것인가라는 생각이 들 수도 있다. C 언어에서는 배열 이름이 갖는 주소 값에 대해서는 메모리에 저장하지 않는다. 주소 값을 저장하고 있다면 형 변환할 필요 없이 그냥 메모리에 있는 주소 값을 찾아서 주면 되지만 C 언어에서는 메모리에 저장하지 않기 때문에 암시적 형 변환이라는 방법을 이용하는 것이다.
이렇게 된 이유는 C 언어 이전에 사용했던 언어를 통해 알 수 있다. C 언어를 사용하기 이전에 B 언어라는 것을 사용했었는데, 실제로 B 언어에서는 배열 이름을 포인터 변수로 두어 배열의 첫 원소의 주소 값을 별도로 저장했었다. C 언어로 넘어오게 되면서 B 언어처럼 별도로 포인터 변수를 두어 주소를 저장하는 것에 대해서 메모리가 사용되는 것을 없애고자 했고, 그렇게 C 언어에서는 배열 이름을 포인터 변수로 메모리에 두는 것이 사라졌다. 하지만 B 언어에서 C 언어로의 통합에서 진통을 없애고자 메모리에 주소 값을 두지는 않지만 주소 값을 이용할 수 있도록 암시적 형 변환이라는 트릭을 도입하게 된 것이다. 따라서 현재 사용하는 C 언어에서는 arr이라고 하는 것이 곧 &arr[0]인 것이고 암시적 형 변환 덕에 arr[0]라는 것을 *arr로 사용할 수 있는 것이다.
Stack Overflow에 따르면 char a[10]에서 &a에 대한 타입과 &a[0]의 타입을 확인 했을 때, 후자는 char *가 나온데 반해 전자는 char (*)[10]과 같이 나온 것을 통해 단항 연산자 &에 대해서 배열 이름은 배열을 의미한다고 적혀 있다.
그렇다면 배열 이름에 대해서 암시적 형 변환이 일어난 포인터는 포인터가 참조하는 주소 값을 바꿀 수 있을까? 배열이 선언 되었을 때, 배열의 원소 값은 바꿀 수 있었다. 마찬가지로 형 변환이 일어난 포인터에 대해서 포인터가 참조하는 값은 인덱스를 벗어나지 않는 한에서 값은 바꿀 수 있기 때문에 상수 포인터는 아니다. 하지만 직접 코드를 짜서 수행해보면 알겠지만 배열이 참조하고 있는 그 공간 자체는 바꿀 수 없다. 즉, 배열 이름의 암시적 형 변환이 일어난 포인터는 별도로 명시하지 않았음에도 포인터 상수로 이용하게 된다. (다시 말하면, 포인터는 포인터에 대해 수의 증감이 가능했지만, 배열의 경우 배열의 이름이 arr이라면 arr++과 같은 구문은 사용할 수 없다는 것이다. 배열 이름의 포인터는 항상 배열의 첫 원소를 가리킬 수 밖에 없다.
배열은 배열이고, 포인터는 포인터이다. 배열 이름을 포인터로 사용할 수 있는 것은 암시적 형 변환 덕이다. 그렇다면 배열을 포인터로 이용하기 위해서는 어떻게 이용하게 되는지 확인해보자.
7. 배열 포인터
나는 저학년 때 배열을 이용한다고 하면 동적할당을 가장 좋아했던 것 같다. 동적할당을 잘해서가 아니라, 함수를 만드는 방법을 배우고 배열을 인자로 넘길 때 어려워서였다. 1차원 배열에 대해서는 아무런 문제 없이 인자로 넘길 수 있었는데, 꼭 2차원 이상 넘어가면 배열로 선언한 자료에 대해서는 인자로 넘길 때 에러를 맞닥뜨렸기 때문이다. 하지만 동적할당으로 2차원 배열을 만드는 경우에는 단순히 이중 포인터로 넘기면 됐기 때문에 배열 이용에 대해서는 동적할당을 선호했던 기억이 난다.
지금 읽고 있는 배열 포인터 항목부터 시작하여 끝까지 차근 차근 읽으며 메모리에 할당되는 구조를 확인한다면 쉽게 이해할 수 있을 것이다.우선 배열을 포인터로 어떻게 받게 되는지 확인하기 위해선 배열이 메모리에 어떻게 할당되는지 알아보아야 한다.
1) 1차원 배열을 포인터로 받기
int a[10] = {0};
C
복사
위와 같은 코드는 메모리에 할당하면 예상한 것처럼 Linear한 형태로 아래와 같이 할당된다.
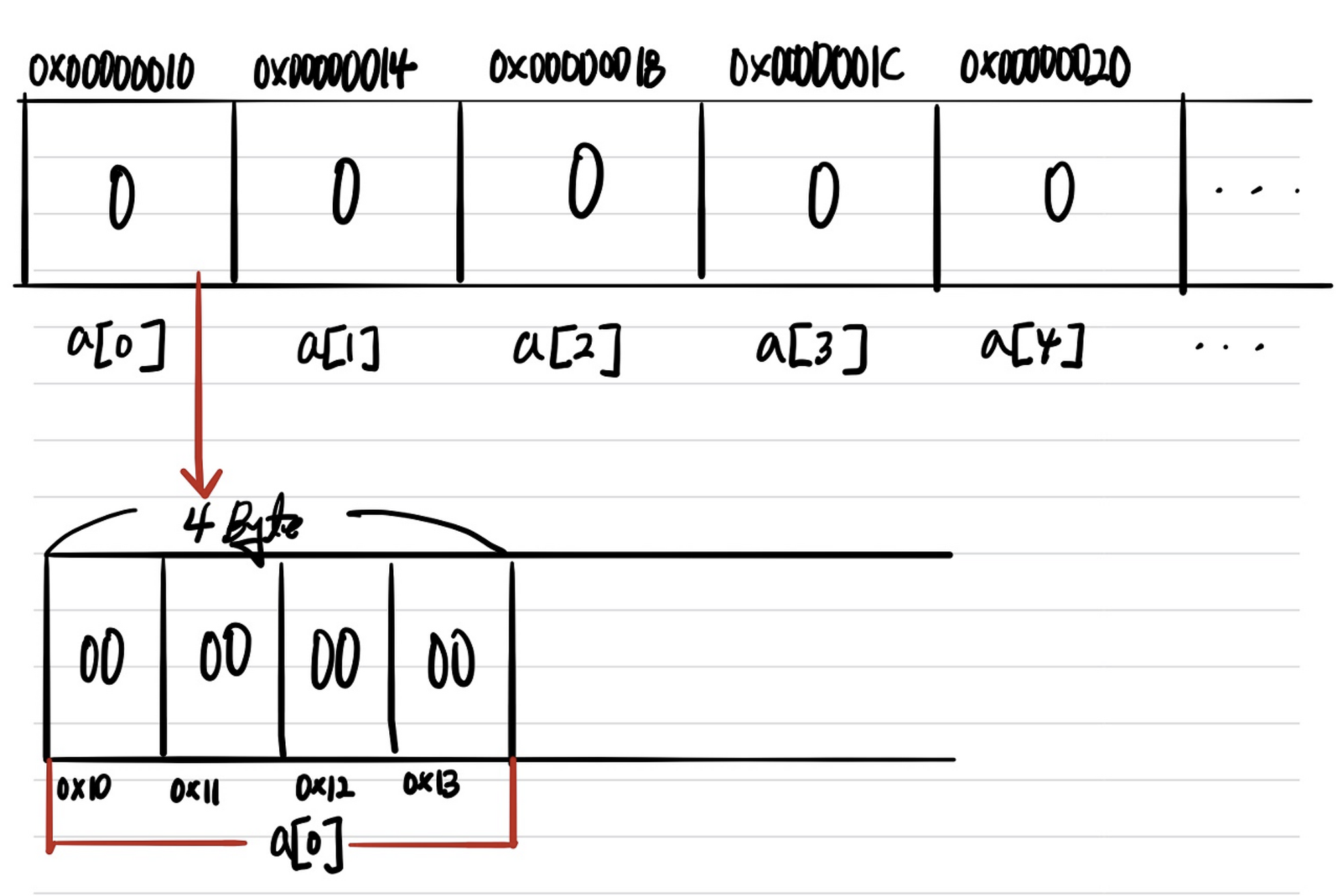
이런 1차원 배열을 포인터로 사용하기 위해선 어떻게 이용하게 될까?
#include <stdio.h>
void printArray(int *parr);
int main()
{
int arr[10] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
printArray(arr);
return 0;
}
void printArray(int *parr)
{
printf("%d\n", parr[4]);
printf("%d\n", *(parr + 4));
}
C
복사
1차원 배열은 메모리 상에 Linear한 형태로 있기 때문에, 단일 포인터로 해당 메모리를 참조하기만 하면 된다. arr을 선언한 후 printArray라는 함수를 실행하게 되면, arr 배열을 단일 포인터 변수 parr로 받게 되면서 parr 포인터 변수에는 arr의 주소 값이 저장된다. 이렇게 인자를 받으면서 메모리에 할당된 포인터 변수는 배열에 접근이 가능하기 때문에 배열처럼 이용할 수 있다.
2) 2차원 배열을 포인터로 받기
2차원 배열은 1차원 배열처럼 포인터로 이용하기 위해서 어떻게 표현할까? 아래의 코드를 2차원 배열도 메모리 상으로 확인해보자.
int a[3][2] = {0};
C
복사
일반적으로 2차원 배열이라 함은 아래 그림처럼 사용된다고 생각할 것이다.
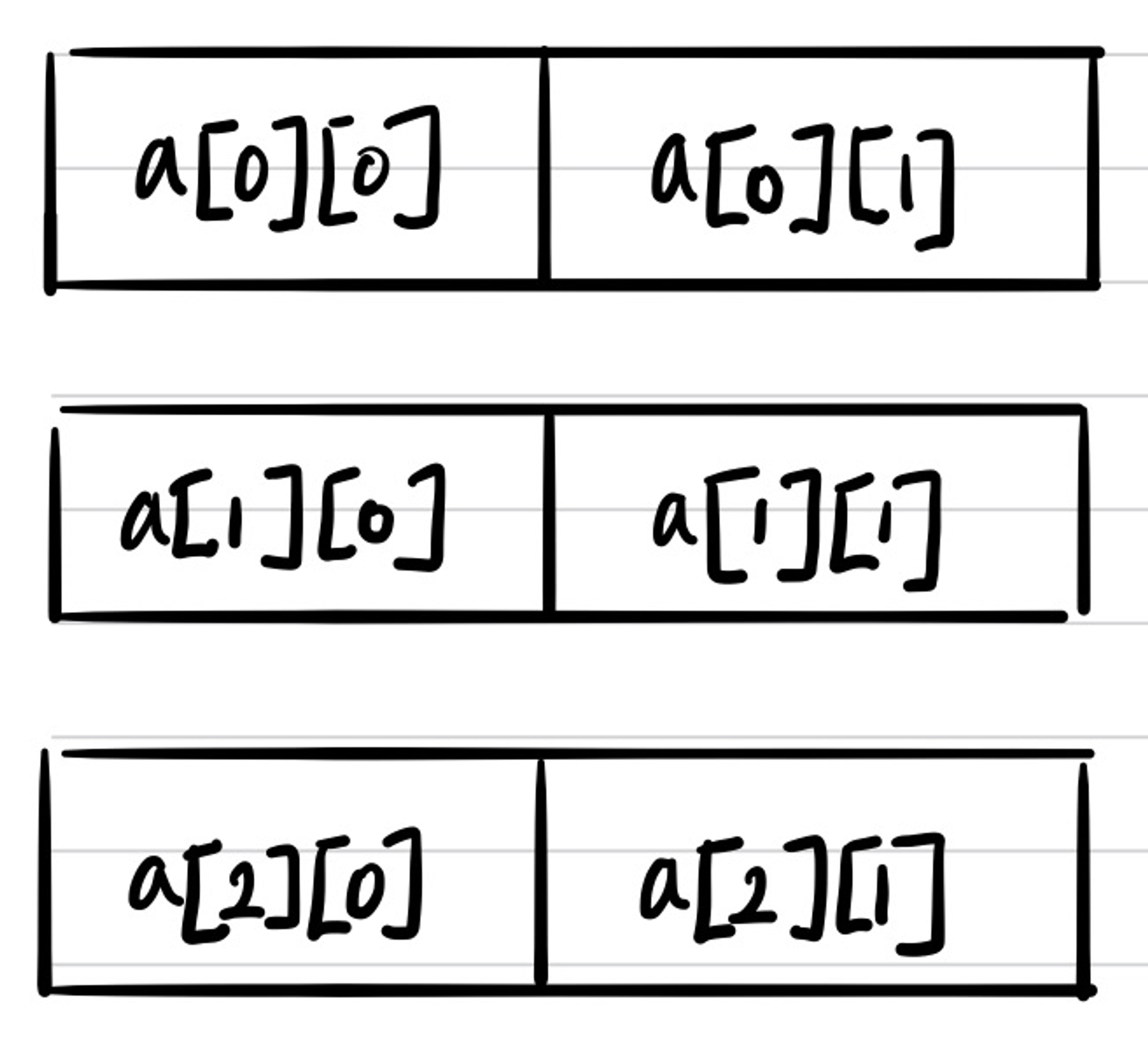
하지만 이는 우리가 생각하기 편하도록 시뮬레이션을 한 것일 뿐이며 실제로는 아래 그림과 같이 2차원 배열도 Linear한 형태로 연속적이게 할당되어 있다.
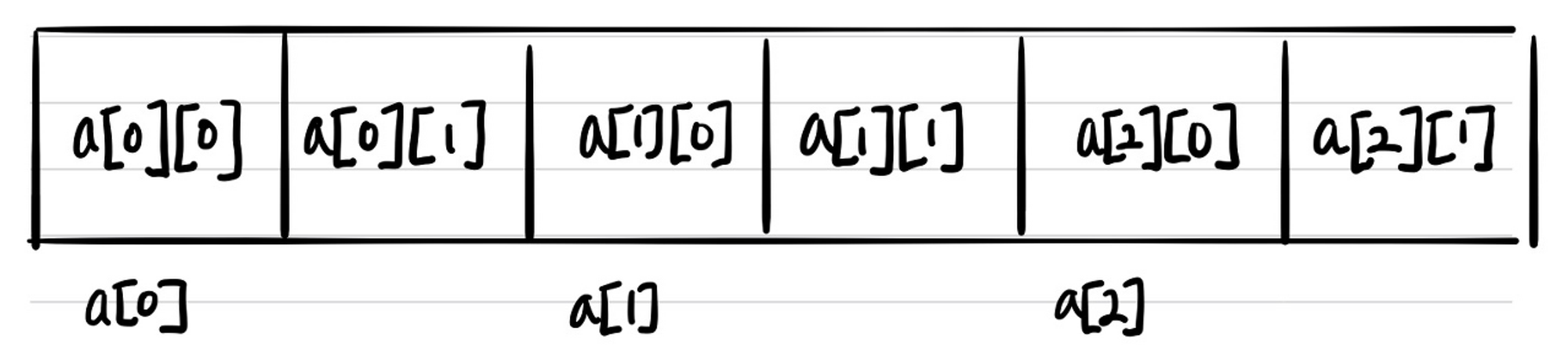
즉, 2차원 배열은 1차원 배열과 다르게 이중 포인터로 이용할 것 같지만 그렇지 않다는 것이다.
#include <stdio.h>
void printArray(int **parr);
int main()
{
int arr[3][2] = {0};
printArray(arr);
return 0;
}
void printArray(int **parr)
{
printf("%d\n", parr[1][1]);
printf("%d\n", *(*(parr + 1) + 1));
}
C
복사
위 코드와 같이 이중 포인터로 받았을 때, Segmentation Fault라는 오류가 발생한다.
일단 이중 포인터를 이용한 2차원 배열의 접근은 틀렸다는 것을 알았으니 단일 포인터로 출력을 시도하면 컴파일 자체가 안 되는 것을 확인할 수 있다. 그럼에도 2차원 배열은 단일 포인터를 이용하여 접근해야 하며, 단일 포인터로 접근하기 위해선 아래와 같이 행과 열에서 열의 크기를 명시해줘야 한다.
#include <stdio.h>
void printArray(int (*parr)[2]);
int main()
{
int arr[3][2] = {0};
printArray(arr);
return 0;
}
void printArray(int (*parr)[2])
{
printf("%d\n", parr[1][1]);
printf("%d\n", *(*(parr + 1) + 1));
}
C
복사
우선 가장 궁금할 수 있는 (*parr)[2]와 *parr[2]의 의미 차이부터 확인하고 가보자. 우선 전자는 배열의 크기가 2로 주어진 배열을 참조하는 배열 포인터이고, 후자는 포인터 주소를 여럿 갖고 있는 포인터 배열이다.
스크롤을 조금 올려서 연산자 우선 순위를 나타낸 표를 확인해보면, 이유를 알 수 있다. 단항 연산자 Asterisk의 경우 대괄호보다 연산 순위가 낮기 때문에 아무런 괄호 없이 이용하게 되면 *(parr[2])로 해석된다. 따라서 이는 parr은 배열의 형태를 가지며, 해당 배열은 포인터 변수를 담는 배열이라고 인식하게 되는 것이다. 따라서 배열을 포인터로 참조하기 위해서는 (*parr)[2]와 같이 Asterisk에 대해서 먼저 처리해줘야 한다.
그렇다면 왜 1차원 배열에 대해서는 배열의 행렬에서 열의 크기를 명시하지 않았는데 이용 가능했고, 2차원 배열에서는 열의 크기를 명시해야 사용할 수 있는 것일까? 조금만 더 깊게 생각해보자. 이는 메모리 상에서 원소에 대해 접근하기 위해 인덱스를 계산하는 것과 관련 있다.
1차원 배열의 인덱스 접근 계산

2차원 배열의 인덱스 접근 계산
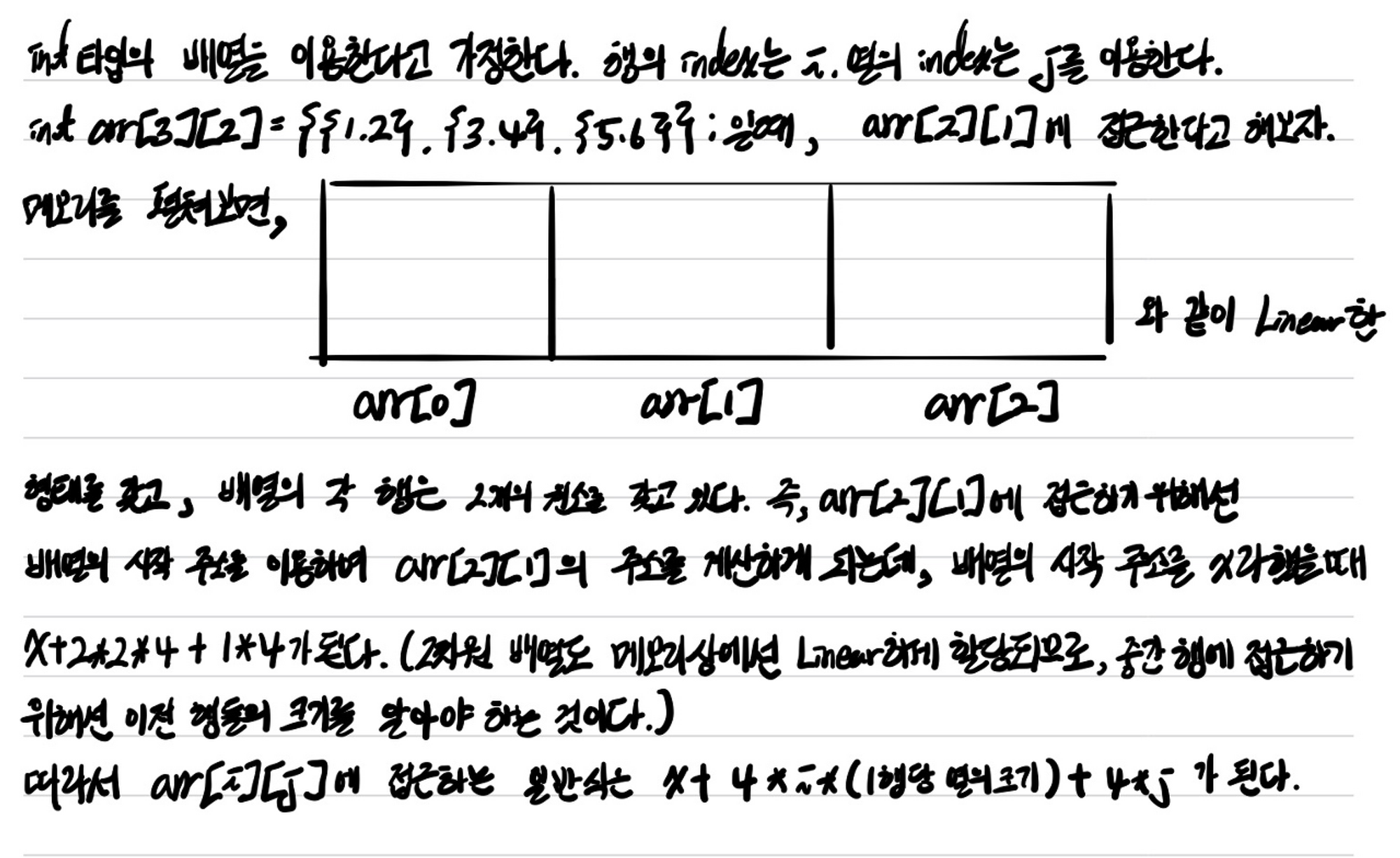
따라서 2차원 배열에 대해서 포인터로 이용하기 위해선 열의 크기를 명시하여 이용해야 하는 것이다.
위 자필의 예시처럼 arr[3][2]를 이용하였을 때, arr과 arr + 1간의 차이는 열의 크기만큼인 8만큼의 주소 값 차이가 나타난다고 할 수 있다. 이를 응용하여 3차원 배열은 어떻게 이용하게 되는지 직접 생각하여 포인터로 활용해보자.

배열 포인터를 이용할 때 유의해야 할 점은 배열의 크기이다. 만일 배열을 함수의 인자로 넣으면서 포인터로 받게 되었을 때, 해당 배열의 전체 크기를 알지 못한다. 따라서 배열의 전체 크기를 모르는 상태에서 gets함수를 사용하는 것은 잠재적 위험이 될 수 있다.
gets 함수가 라이브러리에서 지워진 이유라고 한다.
따라서 배열을 넘겨서 그 크기를 이용해야 할 때는, 배열의 끝을 알릴 수 있는 Sentinel Value (C string에서 Zero Terminator를 사용하는 것과 같이)를 사용하거나 명시적으로 배열의 크기를 함수 인자로 추가로 넘겨주는 행위가 필요할 수 있다.
8. 포인터 배열
배열 포인터의 특이한 문법 구조를 설명하면서, 배열 포인터와 포인터 배열의 차이를 간단히 설명했다. 포인터 배열은 여러 포인터를 배열 형태로 저장한 것이다. (즉, 배열 포인터는 배열을 참조하는 포인터 1개라고 생각하고 포인터 배열은 배열이므로 포인터가 여러 개라고 생각하면 편할 것이다.)
포인터 배열은 말 그대로 주소 값을 여럿 저장하고 있는 배열이기 때문에 아래와 같이 사용하게 된다. 포인터 배열의 크기는 포인터 변수의 크기에 원소 개수 만큼 곱한 크기이다.
#include <stdio.h>
int main()
{
int a = 10;
int b = 20;
int c = 30;
int *parr[3] = {&a, &b, &c};
printf("%d\n", *parr[0]);
printf("%d\n", *parr[1]);
printf("%d\n", *parr[2]);
return 0;
}
C
복사
위 코드처럼 여러 변수의 주소 값을 배열 형태로 저장하는 것이 가능하다.
9. void * 타입의 포인터변수
포인터를 이용하다 보면 여러 예제를 찾을 때도 있을 것이고, 라이브러리를 직접 열어서 확인할 때도 있을 것이다. 나는 포인터에 대해서 아주 조금 알게 되었을 때 도저히 void *라는 것이 왜 존재하고 뭘 의미하는지 알지 못했다. 헷갈리기만 했던 개념이었는데, void *에 대해서 살짝 짚고 넘어가려고 한다.
아주 위에서부터 글을 찬찬히 읽었다면, 포인터 변수를 왜 Asterisk로만 표현하지 않는지 알고 있을 것이다. (모른다면 다시 위에서부터 읽어보자.) 그 이유는, 어떤 타입의 변수를 참조하는지 그 크기를 알아야 하기 때문이다.
int *는 int 타입의 변수를 가리킬 때 사용하고, char *는 char 타입의 변수를 가리킬 때 사용하고, double *는 double 타입의 변수를 가리킬 때 사용한다. 이처럼 각 타입의 포인터 변수들은 해당 타입의 변수를 가리킬 때 사용하게 된다. 그렇다면 void *는 void 타입을 참조하는 것인가?
void voidTypeVariable;
C
복사
다음과 같은 변수를 선언하게 되었을 때 컴파일을 시도하면, 컴파일러는 에러를 내뱉는다. 모든 변수는 메모리에 할당할 수 있도록 크기가 존재하는데, void는 그 크기가 없기 떄문에 변수를 얼만큼의 크기로 메모리에 할당해야 하는지 모르기 때문이다. void 타입의 변수는 이용이 불가능 했지만 void * 타입의 포인터 변수는 선언이 가능할까?
void *voidTypePointerVariable;
C
복사
다음과 같이 선언하면 컴파일러는 void 타입의 변수와 달리 오류를 만들지 않는다. 일단 void *는 포인터 변수이기 때문에 이용하는 주소 체계에 따라 그 크기에 대한 산정이 가능하고, 메모리에 할당할 수 있기 때문이다. 그렇다면 void *의 역할은 무엇일까? 각 타입의 포인터 변수는 해당 타입의 변수를 참조하는데 이용이 되었으니, void *도 void 타입의 변수를 참조하는데 사용될까? void 타입 변수는 존재할 수 없는데 void *타입의 포인터 변수는 어떻게 이용할까?
void 타입의 변수는 존재하지 않기 때문에 void *의 포인터 변수는 아무 쓸모없는 것처럼 보일 수 있지만, 굉장히 자주 쓰이고 중요한 의미를 갖는다. void라고 하는 것은 아무런 타입이 존재하지 않는다는 의미를 갖기 때문에, void *는 어떤 타입의 변수도 가리킬 수 있다. 어떤 타입의 변수도 가리킬 수 있는 장점이 있지만, Asterisk를 통해서 데이터를 Retrieve할 때는 주의해야 한다. 특정 작업 없이는 가리킨 변수의 데이터를 (얼만큼의 크기의 바이트를 가져와야 할 지 명시되어 있지 않기 때문에) Retrieve할 수 없다. 특정 작업이라 함은 포인터 변수의 형 변환(Type Casting)이다.
형 변환에 대해서는 void * 타입의 포인터 변수에 대해서만 가능한 것은 아니다. char *도, int *도, double *도 모두 다른 타입의 포인터 변수로 형 변환이 가능하다. 어떤 타입의 포인터 변수가 올지 몰라도, void * 타입으로 이용하지 않고 double *나 int * 같이 명시해서 필요할 때마다 형 변환을 해주면 되지 않을까? 당연히 가능하다. 하지만 이는 프로그래머에게 혼동을 야기할 수 있다. 특정 타입을 명시했다는 것은 그 타입을 이용하라는 의미이기 때문에, 형 변환이 가능하다고 해서 double *를 받는 곳에서 int *를 이용하는 그런 행위는 바람직 하지 않다. 따라서 어떤 타입의 포인터 변수가 와도 된다는 의미를 코드로 나타낼 때 void * 타입의 포인터 변수를 이용하게 된다.
이런 void * 타입의 포인터 변수를 이용하는 경우는 동적할당을 할 때도 확인할 수 있다. 아래 코드를 보면 알 수 있듯이, 동적할당을 통해 Heap 공간에 메모리를 할당한 후에는 그 할당한 공간에 대해서 특정 타입의 크기만큼 접근해야 한다고 형 변환하여 이를 명시해준다. 동적할당을 담당하는 함수의 return 타입이 void *타입임을 유추할 수 있다.
int arrSize = 10;
int *arr = (int *)malloc(sizeof(int) * arrSize);
C
복사
10. 이중 포인터
이중 포인터에 대해서만 다루면 전반적인 포인터에 대한 개념은 마무리 지을 수 있을 것이다. 이중 포인터는 그리 어려운 개념은 아니다.
단일 포인터 int *가 있다고 해보자. 이 단일 포인터는 int 타입의 변수를 참조해, 해당 변수의 주소를 담는 역할을 한다. 그러니 그림으로 표현하면 아래와 같다.
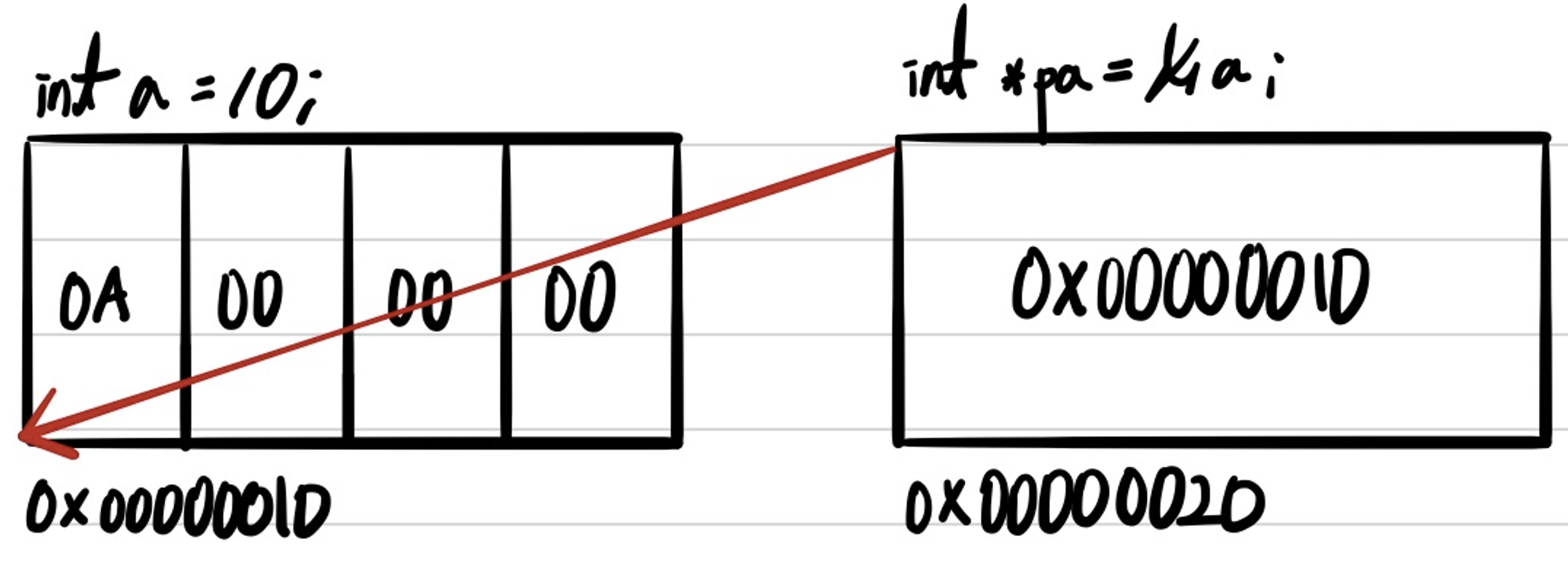
그렇다면 이중 포인터에 간단히 생각해보자. Asterisk가 1개 있는 단일 포인터 변수가 Asterisk가 달려있지 않은 변수를 참조하는 방식이었으므로, Asterisk가 2개 있는 이중 포인터 변수는 Asterisk가 1개 있는 단일 포인터를 참조한다고 받아들이면 편할 것이다. 즉, 이중 포인터는 단일 포인터를 참조해 단일 포인터의 주소 값을 가지는 변수라고 보면 된다.
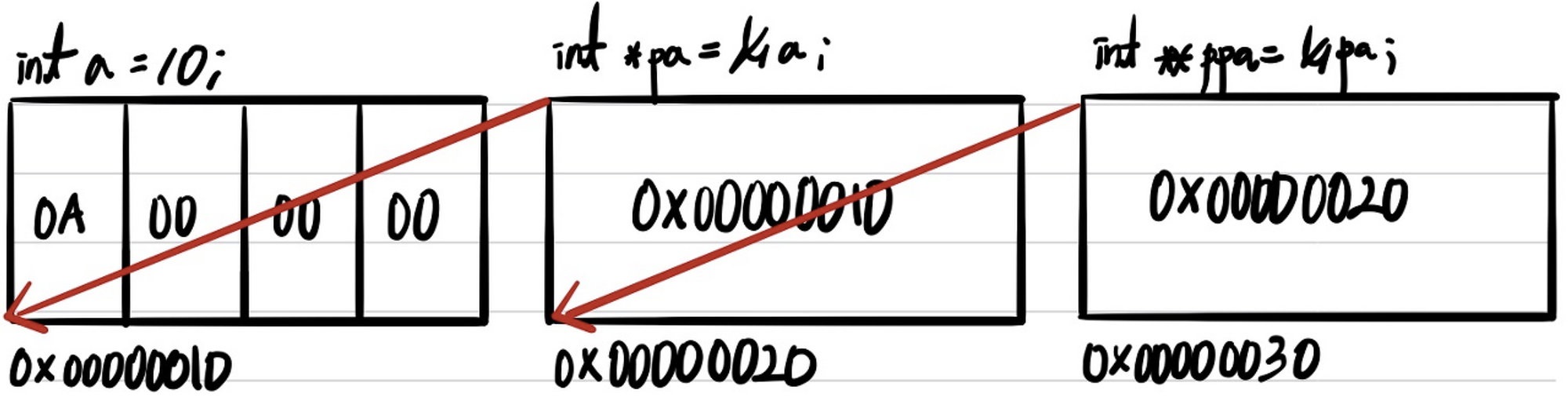
예를 들어 int 타입의 변수 a를 참조하는 포인터 변수가 pa였다면, int *타입의 포인터 변수 pa를 참조하는 포인터 변수는 int **타입의 ppa라고 보면 된다. (int 타입의 변수를 참조하는 포인터를 참조하는 포인터 변수가 int **타입의 포인터 변수이다.)
이중 포인터는 단일 포인터를 참조하고 있기 때문에, 이중 포인터로 선언된 포인터 변수에 대해서 Asterisk를 1개를 붙여 데이터를 Retrieve하게 되면 이중 포인터가 갖고 있는 주소 값에 해당하는 변수가 갖는 값이 된다. 위 예시로 이중 포인터 변수 ppa에 Asterisk 1개를 붙인 후 결과를 출력해보면, 0x00000010이라는 값이 나오므로 변수 a를 의미하게 된다. 그렇다면 이중 포인터 변수에 Asterisk 2개를 붙여 데이터를 Retrieve하면 어떤 결과가 나올까? 조금 복잡하니 위 예시를 통해 결과 값을 예측해보자. *ppa를 통해 pa의 값이 나왔으므로, **ppa를 출력해보면 *pa의 결과가 나올 것이므로 10이라는 결과가 나오게 된다. 이해가 되지 않는다면 아래의 그림을 참고해보자.
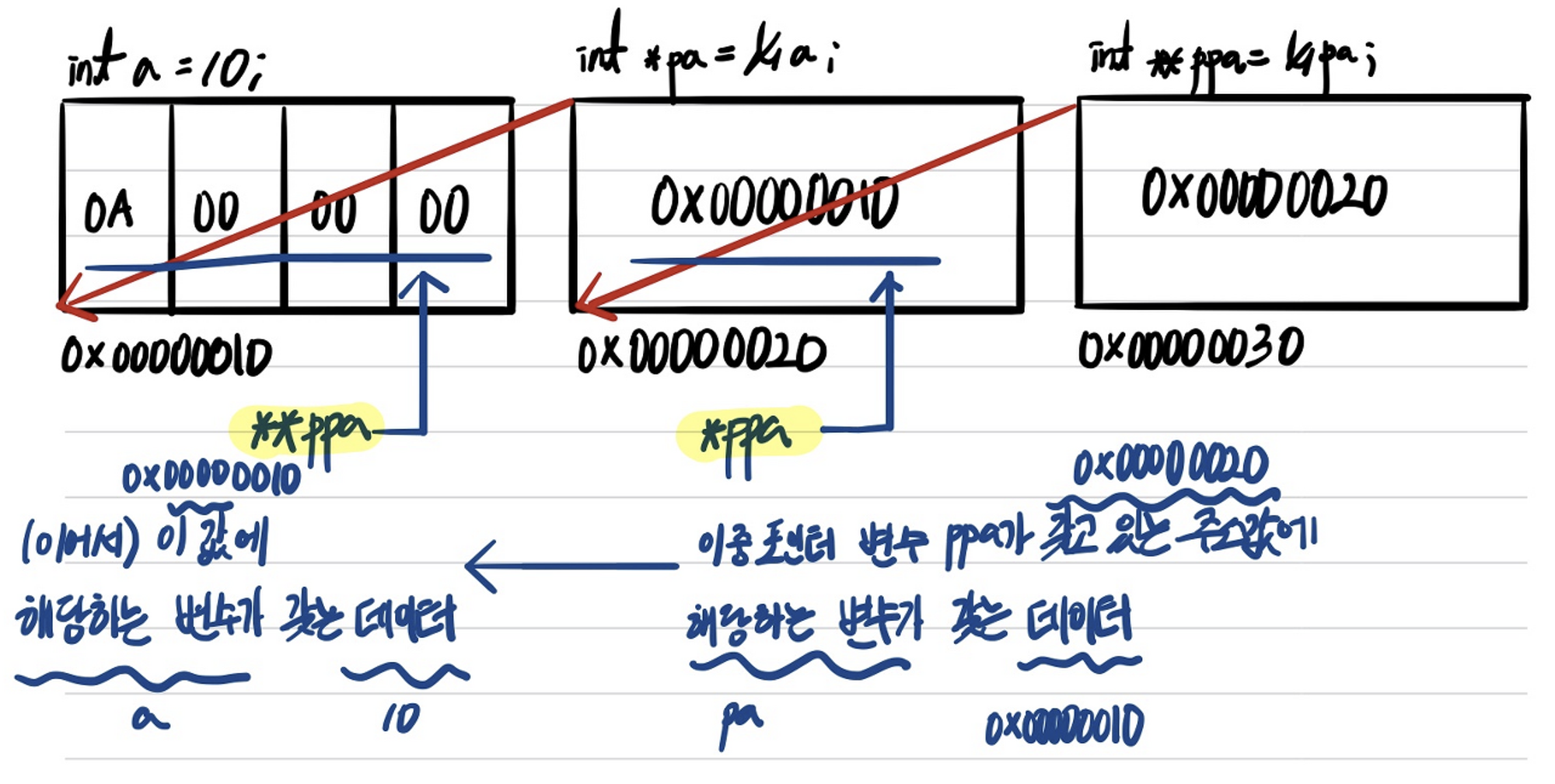
이중 포인터에 대한 개념은 위와 같다. 이중 포인터를 마무리 하기 전에 코드 예시를 통해 확인해보자.
#include <stdio.h>
int main()
{
int a = 10;
int *pa = &a;
int **ppa = &pa;
printf("a의 주소 -> %p\t\t\ta의 값 -> %d\n", &a, a);
printf("pa의 주소 -> %p\t\t\tpa의 값 -> %p\n", &pa, pa);
printf("ppa의 주소 -> %p\t\t\tppa의 값 -> %p\n", &ppa, ppa);
printf("\nAsterisk 1개 ppa 값 -> %p\t\tpa의 값 -> %p", *ppa, pa);
printf("\nAsterisk 2개 ppa 값 -> %d\t\t\t*pa의 값 -> %d\n", **ppa, *pa);
return 0;
}
C
복사
위 코드는 위에서 자필로 제시한 예시와 변수의 값, 변수의 포인팅이 동일하게 작성되었다. 주소 값 배정은 컴퓨터가 알아서 해주기 때문에 예측한 값과 정확히 일치하진 않겠지만, 이 출력 결과와 추측한 결과를 비교해보자.
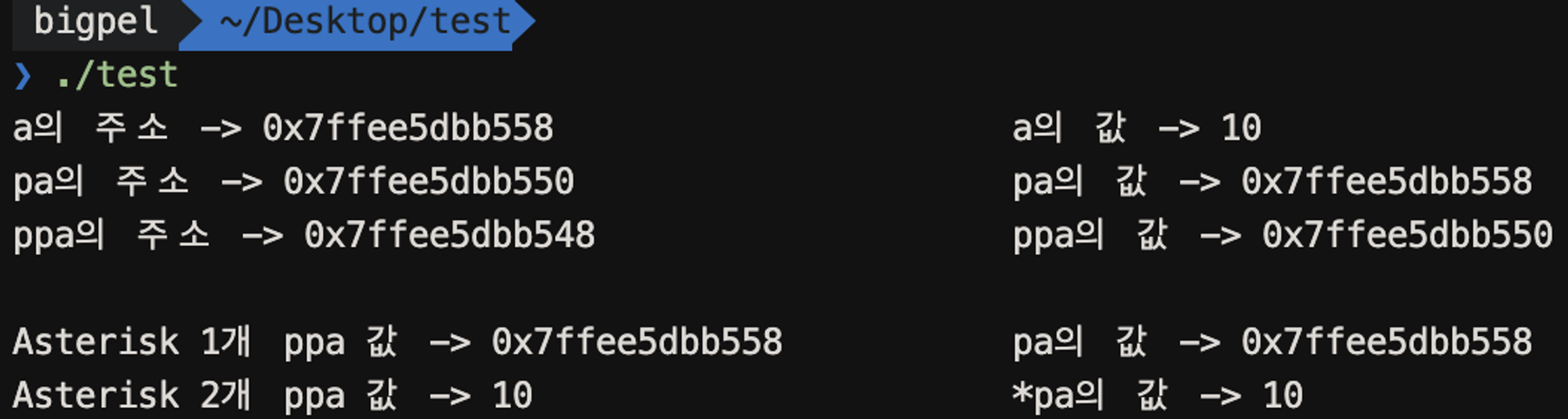
제시된 코드를 실행해서 나타내면 위의 그림과 같다. 개념 정리로 제시된 예시와 지칭하는 값과 주소가 동일한 것을 확인할 수 있다. 따라서 이중 포인터 변수를 이용하면 단일 포인터와 단일 포인터의 값, 그리고 단일 포인터가 지징하는 주소와 단일 포인터가 지징하는 주소의 값에 대해서 접근할 수 있었다.
이중 포인터 변수는 굉장히 유용하게 사용될 수 있으며, 특히 동적할당으로 '유사' 2차원 배열을 만들 때도 (2차원 배열과 이중 포인터의 차이에서 밝히도록 하겠다.) 유용하게 사용할 수 있다. '유사' 2차원 배열을 만드는 것 이외에 어떤 경우에 이용될 수 있을까? 우리가 작성한 소스 코드를 실행 파일로 만들고, 해당 실행 파일을 터미널에서 구동하면서 실행 파일의 인자 값을 주는 경우 이용될 수 있다. 만일 C 언어와 C++을 터미널 환경에서 gcc 혹은 g++을 통해서 컴파일하고 실행하는 것이 아니라면 이 상황이 생소할 수 있다. 대부분의 포인터를 처음 배우는 대학교 새내기일수록 위 환경 보다는 Microsoft의 Visual Studio를 이용하면서 디버그 하지 않고 시작을 통해서 실행하는 것이 더 익숙할 것이다.
main문을 실행할 때 사용되는 argc, argv에 대한 간단한 설명하면서 이중 포인터에 대해서 마무리하겠다.
#include <stdio.h>
int main(int argc, char **argv)
{
int index;
printf("%d\n", argc);
for (index = 0; index < argc; index++)
{
printf("%s\n", argv[index]);
}
return 0;
}
C
복사
위와 같이 argc와 argv가 붙은 코드를 본 적 있는가? 솔직하게 나는 새내기 때 해당 코드를 보고서 C 언어에 대해서 흥미가 떨어졌었다. 아니 뭐 이런 간단한 거로 흥미가 떨어져? 할 수도 있겠지만, 나는 이전까지 C 언어를 배울 때 꼼꼼하게 C 언어를 공부하지 않았고 흥미가 떨어질대로 떨어진 상황이었다. 지금 와서 생각해보면 정말 피식하면서 정말 제대로 공부 안했구나, 검색 한 번 해보면 해결될 일을... 얼마나 핑프였던 거야..?하지만 아마 대부분 프로그래밍을 C 언어로 처음 배우는 사람들은 멘탈 제대로 흔들리지 않을까 싶다.
당시 나는 조교님께 argc, argv가 뭘 하는 거냐고 물었는데 그냥 인자 받는거야~라는 대답만 들었다. 나에게 있어서 C 언어를 실행하는 방법은 디버그 하지 않고 실행이 전부였는데, main 함수의 인자인건 알겠는데... 조교님이 말씀하시는 인자가 뭘까?, 쟤는 왜 int고 쟤는 왜 char야?, 근데 왜 그냥 char도 아니고 **야?, **면 주소의 주소인가? 왜 주소의 주소를 main에 받지?, main 함수에 인자는 누가 넣어주는데?와 같은 수 많은 질문들이 떠올랐었다. 지금 이 글을 여기까지 읽어준 인내심 깊은 분들도 비슷한 고민을 했었거나 하고 있지 않을까 싶다.
우선, 소스 코드를 작성하여 컴파일 하게 되면 목적 파일이 나오고 여러 목적 파일들과 라이브러리들을 링커를 통해 묶으면서 실행 파일이 만들어진다. (잘 모르겠으면 컴파일러에 대해서 간단히 설명한 작성 글이나 C 언어 컴파일에 대해서 검색해보자.) 이렇게 만들어진 실행 파일을 구동하게 되면, 런 타임으로 진입하기 위해 운영체제는 소스 코드의 main 함수를 찾게 된다. 그리고 실행할 때 실행 옵션으로 준 인자들을 main 함수를 실행시키면서 알아서 넣게 된다. argc는 인자의 개수, argv는 인자의 상세한 문자열을 의미한다. 따라서 argc는 인자의 개수를 세는 것이므로 int 타입이고, argv는 상세한 문자열이므로 char **이 된다.
위에서 주어진 코드를 통해서 살펴보자. 위 코드의 스크립트 이름은 test.c라고 하고, 실행 파일의 이름도 test라고 해보자. 그렇다면 위 파일을 실행하게 되면 어떤 결과가 나올까?
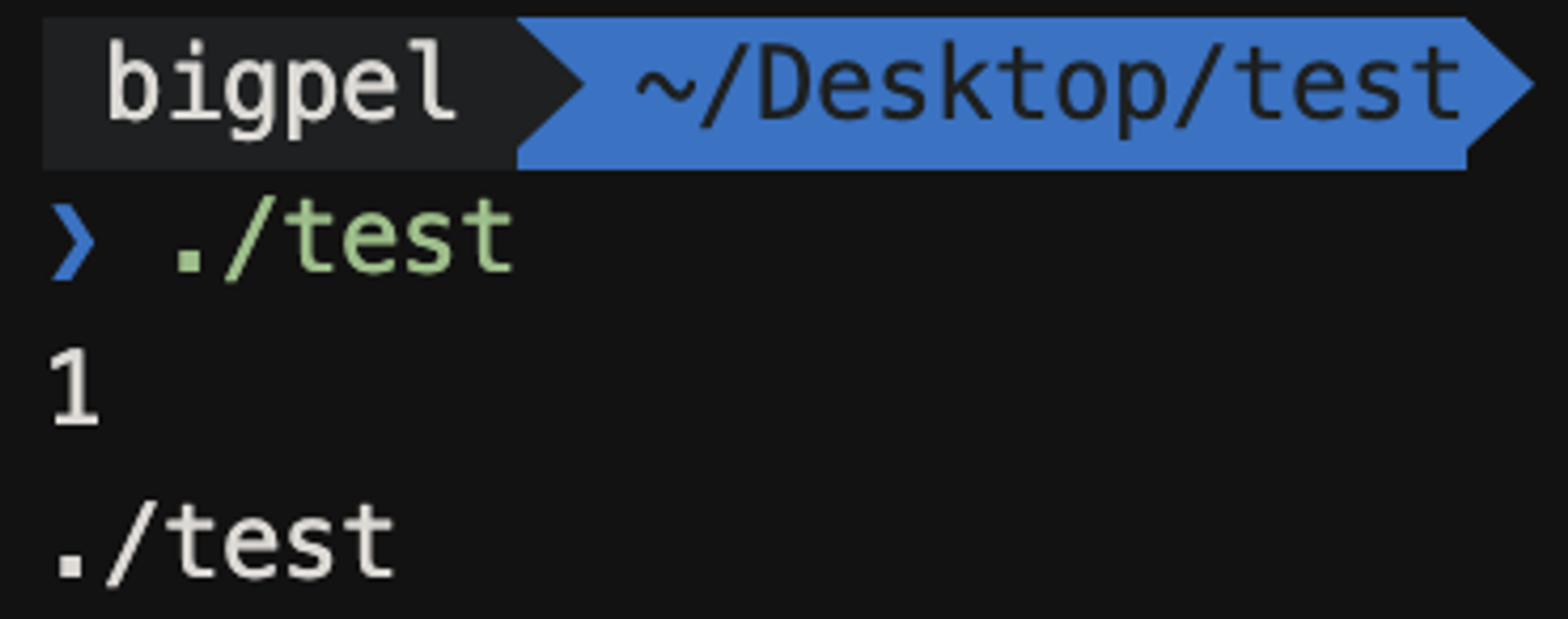
아무런 인자를 주지 않고 실행을 시켰는데 (MacOS, Linux 계열에서의 실행 방법은 .라고 하는 현재 디렉토리 아래(/)에 파일 이름을 주면 실행된다.) 인자가 1개, 그 인자의 상세한 문자열은 실행 파일의 경로가 나왔다. 즉, 내가 프로그램을 실행하면서 아무런 인자 값을 넣어주지 않고 실행을 하더라도 인자는 최소한 1개는 들어가며 그 인자는 실행 파일의 경로가 들어가게 된다. 그렇다면 위 코드의 인자로 hi, new, program이라는 인자를 주었을 때 argc는 몇이 나오고, argv는 어떤 결과가 나올까?
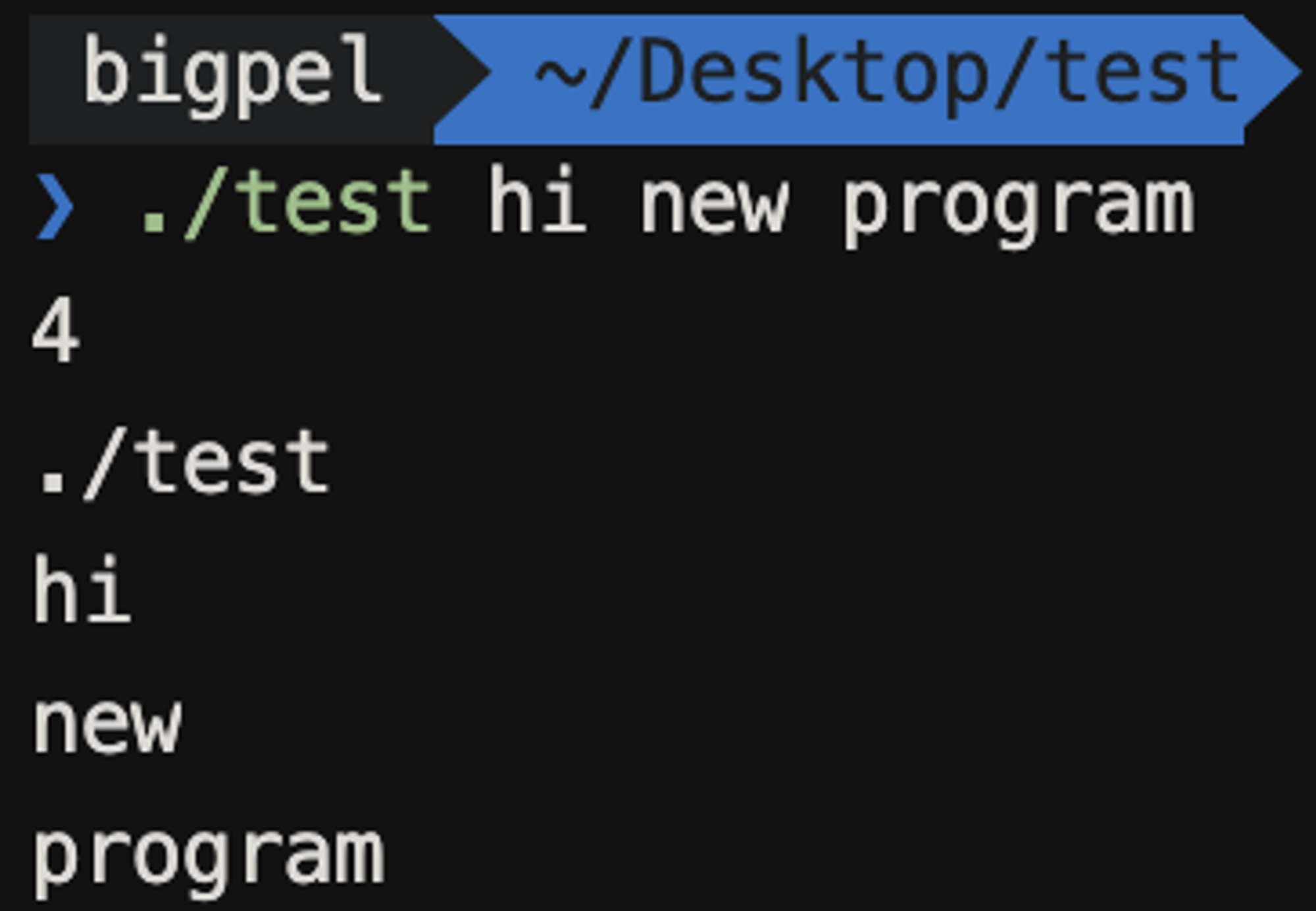
실행 파일의 경로가 들어간 인자 1개, hi, new, program 각 1개씩 하여 총 4개의 인자가 들어갔고, 상세 문자열 역시 ./test, hi, new, program으로 4개가 나온 것을 확인할 수 있다. 이제 마지막으로 그럼 상세 문자열들을 받는 인자가 왜 char **인지만 알아보자.
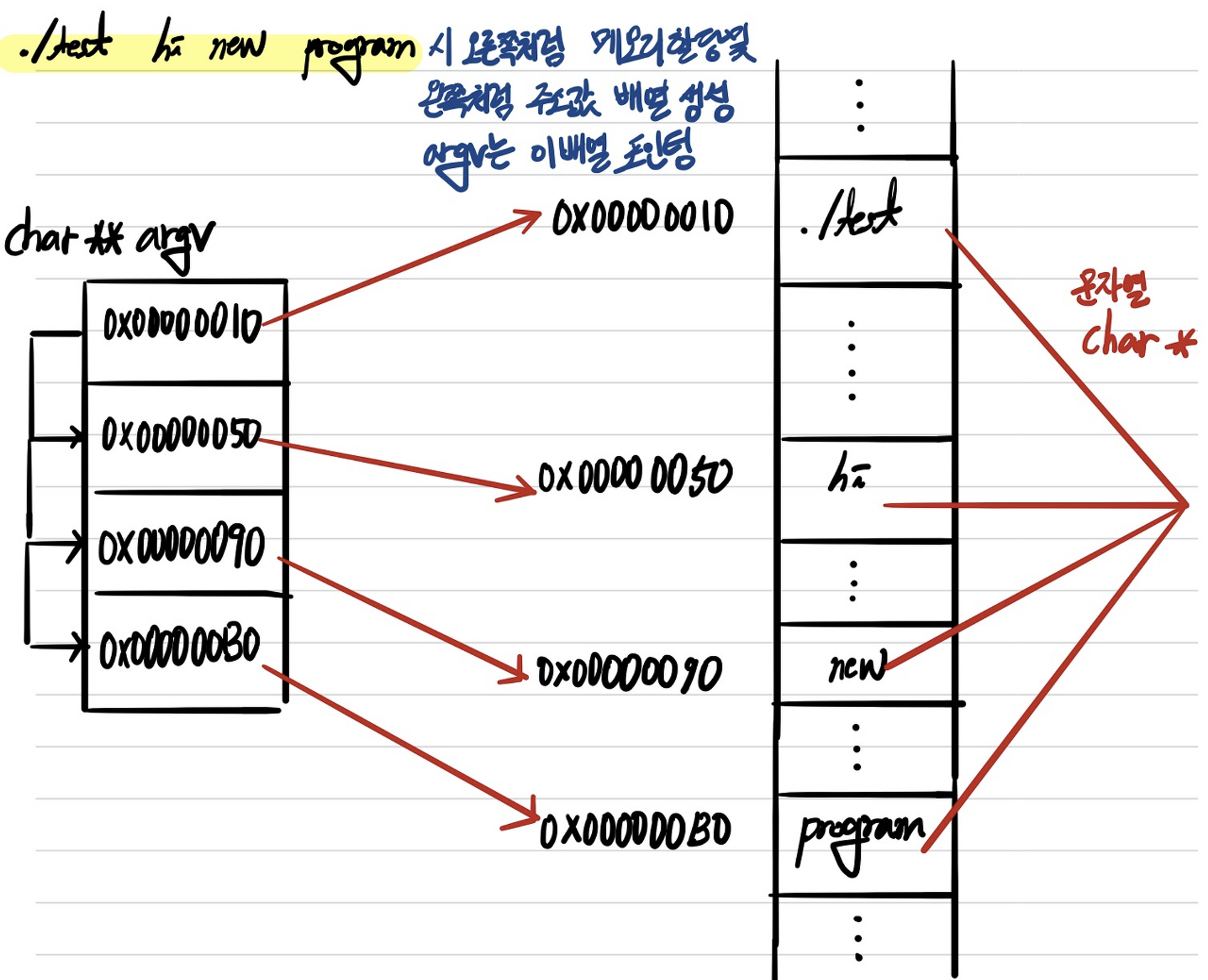
위에서 배열 포인터를 배우면서 2차원 이상의 배열을 지칭하기 위해선 열 혹은 인덱스 계산을 위한 크기가 주어져야 한다고 했다. 그런데 argv에 대한 타입은 char (*)[size]가 아니라 char **로 명시 되었다. 이건 무슨 말일까?
인자로 받은 상세 문자열들은 2차원 배열이 아니라 다음과 같이 생각하면 편하다. (char *)라고 하는 문자열 (문자 배열)을 참조하는 포인터가 바로 char **이다. 조금 쉽게 다시 설명하면, int 타입의 변수를 참조하는 포인터 변수가 int *타입의 포인터 변수였듯이, char **타입의 포인터 변수라고 하는 것은 (char *)타입의 변수를 참조하는 것이라고 생각하면 된다는 것이다.
따라서 실행 파일을 구동하게 되면, argv라고 하는 포인터 변수는 가장 먼저 들어오는 인자인 실행 파일의 경로를 나타내는 문자열의 주소를 참조하고 있는 상태가 된다. 그리고 for 루프를 통해 argv[index]라고 하면 *(argv + index)로 그 다음 문자열의 주소를 참조하게 되므로, 실행 파일 경로 이 후에 hi, new, program이라고 하는 인자의 상세 문자열들이 출력되는 것이다. 아래 그림과 같은 상태로 이해하면 편할 것이다.
11. 2차원 배열과 이중 포인터의 차이
이중 포인터 변수에 대해서 수행한 예제 코드 아래에 동적할당을 통해서 2차원 배열을 만들 때 이중 포인터를 활용한다고 적으면서, 이에 대해 '유사' 2차원 배열이라고 명시했다.
아마 배열 포인터 부분에 대해서 잘 읽었다면 배열이라고 하는 것이 메모리에 어떻게 할당되는지 확인했을 것이다. 2차원 배열이 메모리에 할당되는 구조와 아래 코드를 통해 생성한 배열의 메모리에 할당된 구조를 비교하며 생각해보자.
#include <stdio.h>
#include <stdlib.h>
void printRealArrayAddress(int (*p)[5], int rowSize);
void printSimilarArrayAddress(int **p, int rowSize, int colSize);
int main()
{
int index;
int realArray[2][5];
int **similarArray;
similarArray = (int **)malloc(sizeof(int *) * 2);
for (index = 0; index < 2; index++)
{
similarArray[index] = (int *)malloc(sizeof(int) * 5);
}
printRealArrayAddress(realArray, 2);
printf("\n");
printSimilarArrayAddress(similarArray, 2, 5);
for (index = 0; index < 2; index++)
{
free(similarArray[index]);
}
free(similarArray);
return 0;
}
void printRealArrayAddress(int (*p)[5], int rowSize)
{
int i, j;
for (i = 0; i < rowSize; i++)
{
for (j = 0; j < 5; j++)
{
printf("Real Array %d row, %d col Address -> %p\n", i, j, &p[i][j]);
}
printf("\n");
}
}
void printSimilarArrayAddress(int **p, int rowSize, int colSize)
{
int i, j;
for (i = 0; i < rowSize; i++)
{
for (j = 0; j < colSize; j++)
{
printf("Similar Array %d row, %d col Address -> %p\n", i, j, &p[i][j]);
}
printf("\n");
}
}
C
복사
배열 포인터를 하면서 2차원 배열에 대한 메모리 구조를 배울 때, 2차원 평면처럼 생성될 것 같은 2차원 배열이 실제로는 Linear한 구조로 메모리에 할당되는 것을 확인할 수 있었다. 예제의 코드를 실행하여 보면 알겠지만, 2행 5열로 생성된 realArray의 주소 값들은 int 타입의 배열이기 때문에 주소 값들이 4씩 차이나며 Linear하게 생성된 것을 볼 수 있다. 반면 동적할당으로 생성한 '유사' 2차원 배열은 열끼리는 주소 값들이 4씩 차이나며 Linear한 것을 볼 수 있지만, 행간의 주소를 살펴보면 Linear하지 않다. 이제 조금 느낌이 오는가? 동적할당으로 2차원 배열을 만들 때 행에 대해서 먼저 생성을 하고, 각 행에 대해서 열들을 생성하는 것을 통해 동적할당 수행 시 메모리 할당을 유추할 수 있다.
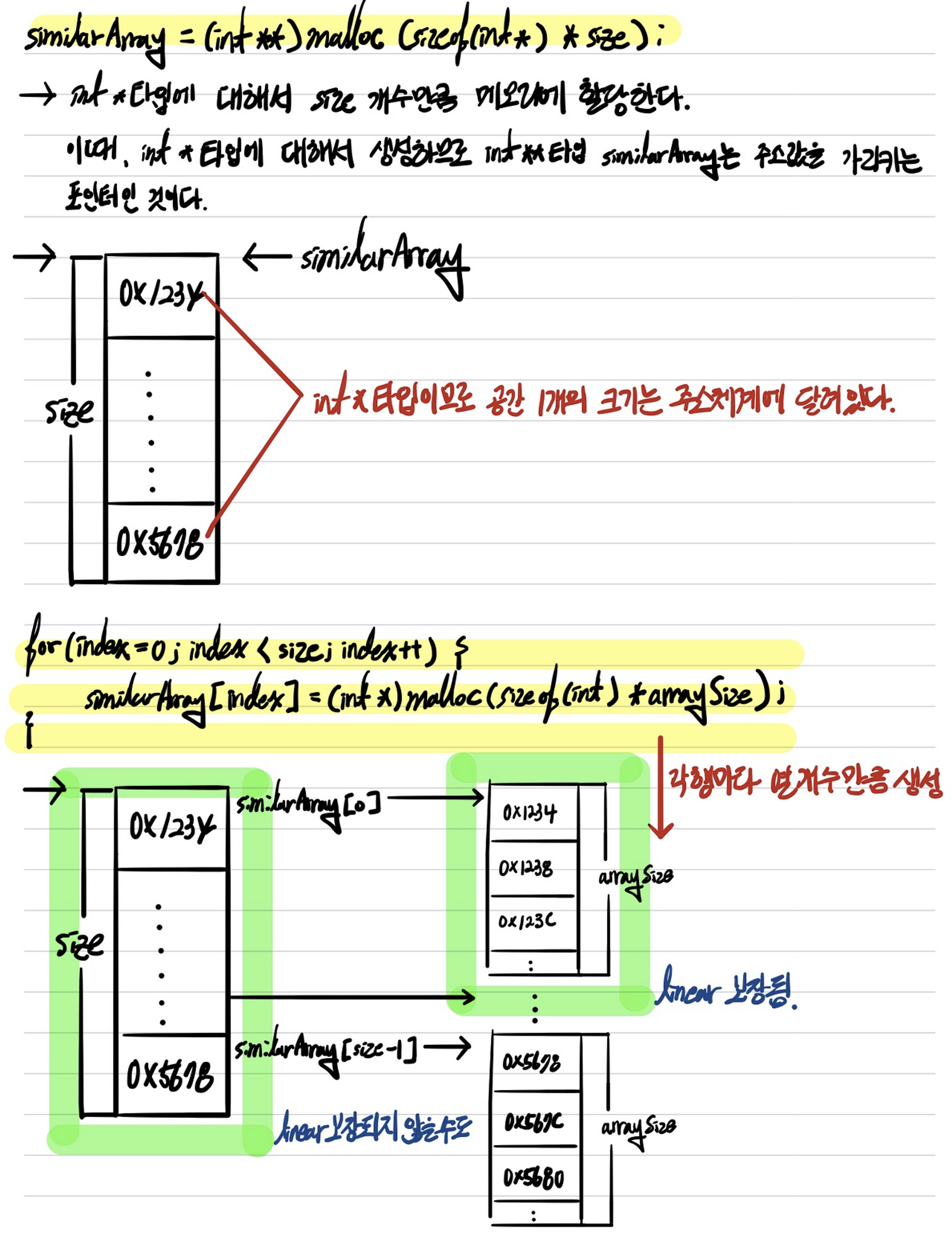
동적할당을 통한 2차원 배열 생성은 위 그림과 같다. (실제 2차원 배열의 메모리 구조는 배열 포인터 항목을 참고하면 된다.) 따라서 이중 포인터를 이용하여 생성한 2차원 배열은 엄밀히 말하면 정확히 2차원 배열이라고는 할 수 없다.
심지어 일반적인 2차원 배열과 이중 포인터 변수를 이용하여 생성한 2차원 배열은 함수에 인자를 받을 때도 다르다. 예시 코드에 제시된 두 2차원 배열의 인자를 유심히 보자. 실제 2차원 배열은 열의 크기가 필요한 단일 포인터로 인자를 받게 되고, 동적할당으로 생성한 2차원 배열은 이중 포인터를 받게 된다.
실제 2차원 배열은 Linear한 메모리 구조를 갖기 때문에 단일 포인터를 이용하며, 특정 인덱스의 원소에 접근하기 위해서는 주소 값을 구해야하고, 그러려면 열의 크기가 필요했다. 따라서 단일 포인터에 열의 크기가 몇이나 되는 배열을 이용할지 크기를 명시해야 했다. 반면 이중 포인터 변수의 동적할당으로 생성한 2차원 배열은 각 행의 열들에 대해서는 Linear (각 행들의 열에 접근할 때는 단일 포인터 이용 가능) 하지만, 사용되는 행들은 뿔뿔이 흩어져 있다. 이중 포인터는 이렇게 뿔뿔이 흩어진 행들의 (단일 포인터로 접근하는) 주소들에 대해서 참조하고 있기 때문에 이중 포인터로 인자를 받게 된다. (그림을 참고하면서 보면 조금 더 이해가 편할 것이다.)

