


Installing Redis on macOS
brew를 통해서 redis를 설치한다. brew가 설치 되어 있지 않다면, brew.sh라는 주소를 통해 brew를 먼저 설치한다.
brew install redis
명령어를 통해서 redis를 설치하면, 서버 재부팅 시 자동으로 redis를 켤지에 대한 옵션을 명령어를 통해 줄 수 있다.
redis 자동 실행 켜기
brew services start redis
redis 자동 실행 끄기
redis-server /usr/local/etc/redis.conf
redis 정상 실행 확인하기
redis-cli ping
Getting and Setting Basic Values
redis에 key & value를 지정하는 것은 JavaScript에서 Object에 key & value를 지정하는 것과 굉장히 유사하다.
redis 실행 (일종의 서버)는 brew를 통한 redis 실행 명령어로 켜둘 수 있고, 조작은 node-redis라는 라이브러리를 통해서 JavaScript로 전반적인 조작이 가능하다.

node를 통해 redis를 이용하기 위해선 redis 인스턴스를 위한 redis 라이브러리, redis 조작을 위한 node-redis가 필요하다.
const redis = require('redis');
const redisUrl = 'redis://127.0.0.1:6379';
// const client = redis.createClient(redisUrl);
// 혹은
// const client = redis.createClient(6379, 127.0.0.1);
client.set('hi', 'there');
client.get('hi', (err, val) => {
if(err) {
// err 처리
}
console.log(val);
});
// 혹은 client.get('hi', console.log); 도 가능하다.
JavaScript
복사
redis에 대해서 cloud server를 사용하는 것이 아니라 로컬 서버를 이용하게 된다면 위의 방식으로 클라이언트를 생성하여 쓰면 된다. (로컬에서도 password 지정이 가능할 것이다. 이에 따른 client.auth과정이 필요할 것이다. cloud server를 사용하면 항상 client.auth를 통해 password 검증을 하여 사용해야 한다.)
또한 간단한 key & value 의 set, get은 위와 같이 수행하면 된다. 이번에는 hashing를 통해 조금 더 복잡한 자료구조의 형태로 조작해보자. 일반적으로 redis를 사용하는 이유는 caching에 주된 목적이 있을텐데, 이 hashing은 최종적으로 caching에 굉장히 유용한 작업이다. (일종의 hash index와 같이, 일시적으로 저장한 데이터들에 대해서 bucket을 부여하여 카테고리 별로 나눌 수 있게 된다.)
hashing 작업을 통해 궁극적으로 조작하려는 것은 기존 key & value 쌍을 다시 value로 두는 JavaScript의 Nestsed Object의 형태와 비슷한 Nested Hash이다. 따라서 기존의 set, get과는 달리 hset, hget이라는 함수를 이용하게 된다.
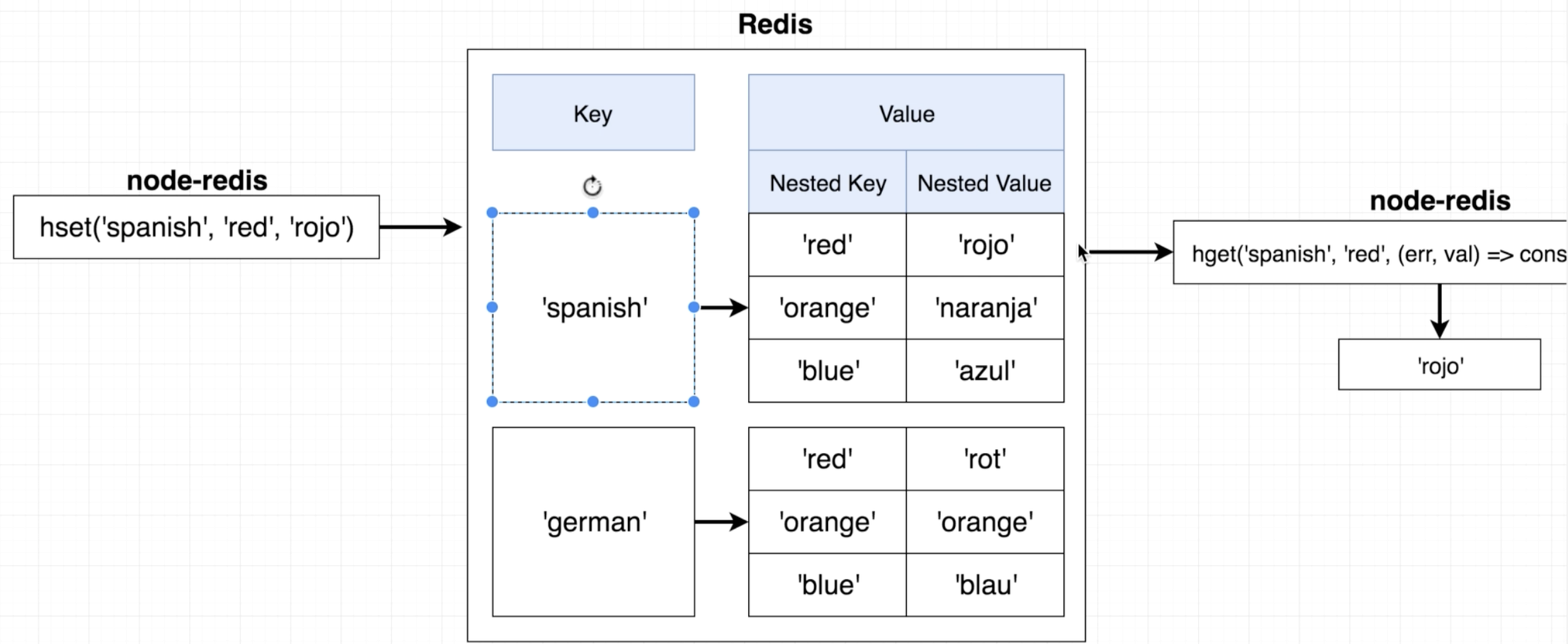
// hset과 hget을 이용할 떄의 redis내의 자료구조는 아래와 같을 것이다.
/* const redisValue = {
spanish: {
red: 'rojo',
orange: 'naranja',
blue: 'azul',
},
german: {
red: 'rot',
orange: 'orange',
blue: 'blau',
}
}; */
client.hset('german', 'red', 'rot');
client.hget('german', 'red', console.log);
JavaScript
복사
** redis를 쓸 때 주로 발생하는 gotcha (실수)가 있다. redis는 저장할 수 있는 데이터는 number와 string, 2가지 옵션 밖에 없다. 따라서 JavaScript에서 Object를 직접적으로 redis에 저장할 수는 없는 것이다. 실제로 JavaScript의 Object를 저장하려고 하면, Object의 형태로 값들이 redis에 저장되는 것이 아니라 Object 자체가 toString 되어 Stringify 된 Object가 통째로 value에 저장된다.
client.set('colors', { red: 'rojo'});
client.get('colors', console.log);
// 결과로
// null '[object Object]'
// 가 나온다.
JavaScript
복사
값이 전달될 때 toString이 되지 않고 올바르게 Object의 형태로 저장하려면, JSON.stringify 함수를 이용해서 전달하면 된다.
client.set('colors', JSON.stringify({ red: 'rojo'}));
client.get('colors', console.log);
// 결과로
// null '{"red": "rojo"}'
// 가 나온다.
client.get('colors', (err, val) => {
console.log(JSON.parse(val));
});
// 단순히 get의 callback으로 console.log를 하는 것이 아니라
// 구체적으로 JSON.parse를 해보면
// { red: 'rojo'}
// 와 같이 원래의 형태를 유지한 object를 볼 수 있다.
JavaScript
복사
결론적으로 redis에 JavaScript의 Object를 저장하고 얻기 위해선, JSON.stringify, JSON.parse의 과정이 필요하다.
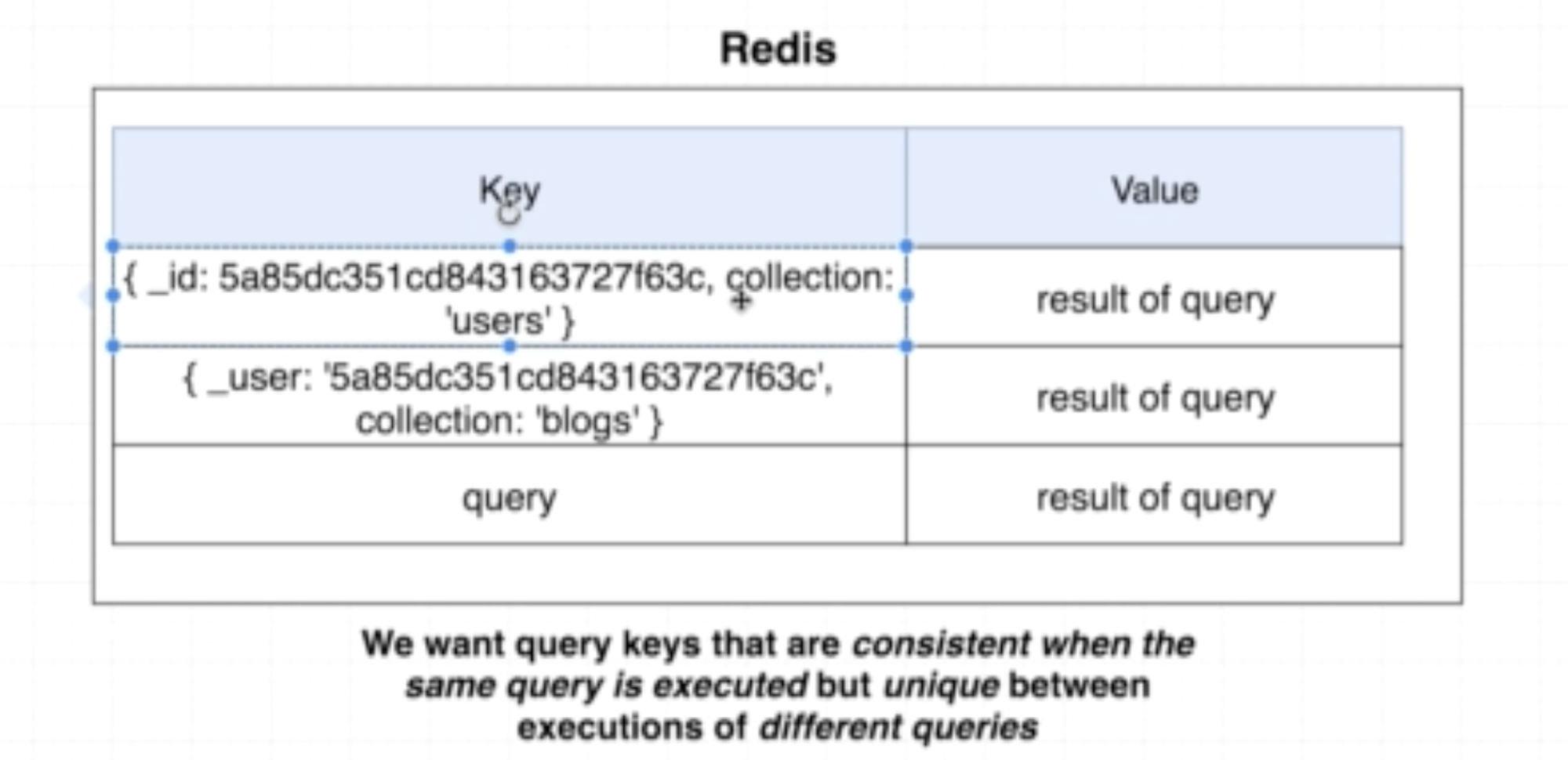
Cache Keys

위 그림을 보다 싶이, Key로 Query를 준다고 했다. 무슨 말일까?
즉, 어떤 경우에 Redis에 Caching을 할 수 있고, 어떤 값을 Key로 써야할까?
우선...
1.
Key (Inner Query)에 따른 결과 (Outer Query의 실행)이 consistent해야 한다.
(a 사용자의 결과를 요청했을 때, 항상 a에 대한 결과만이 도출되어야 한다. a 사용자의 결과를 요청했는데, b 사용자의 결과가 도출되어선 안 된다.)
2.
Key (Inner Query)는 Unique해야한다.
위 조건들을 만족할 때 Inner Query가 Key가 될 수 있고, Redis에 Caching을 할 수 있다.
const blogs = await Blog.find({ _user: req.user.id });
JavaScript
복사
Mongoose를 이용하여 다음과 같은 Query를 날렸다고 가정하고, 해당 Query를 Caching한다고 해보자. 이 때 과연 어떤 값을 Key 값으로 사용할 수 있을까?
위 Query는 1개의 Query 같지만 실제로는 2개의 Query로 구성되어 있는 것을 볼 수 있다. 첫 째는 req.user.id에 걸맞는 사용자 id를 찾는 것이고 (inner), 둘 째는 찾은 사용자 id를 통해 모든 blog들을 찾는 것이다(outer).
이 때, req.user.id를 이용하여 사용자를 찾는 Query가 Key가 될 수 있는지 확인해보자.
1.
사용자에 따라 사용자만의 글이 불러와진다. consistent하다.
2.
사용자를 찾는 Query는 현재 unique하다.
따라서 위와 같은 User, Blog 스키마로 데이터 베이스가 구성된다면, req.user.id를 이용한 Query는 Key가 될 수 있다.
만일! User, Blog, Tweet과 같은 스키마를 가진 데이터 베이스가 있고, Tweet 역시 req.user.id를 이용한 모델이라고 해보자. req.user.id를 통해 사용자를 찾는 Query가 Caching의 Key가 될 수 있을까?
이 경우, Blog의 경우에는 Key로 사용자를 찾는 Query가 되고, Tweet도 사용자를 찾는 Query가 Key가 되기 때문에 Key가 중복된다. 따라서 req.user.id를 통해 사용자를 찾는 Query는 Key가 될 수 없다.
사실 Query가 Key가 된다고는 했지만, 위 예시에 한하여 Query가 아닌 값으로 Key를 저장할 수 있다. 따라서 위의 검증을 거치면 아래 벤다이어그램 처럼 되므로 실제 redis에서 저장되는 형태는 두 번째 그림과 같이 나온다.
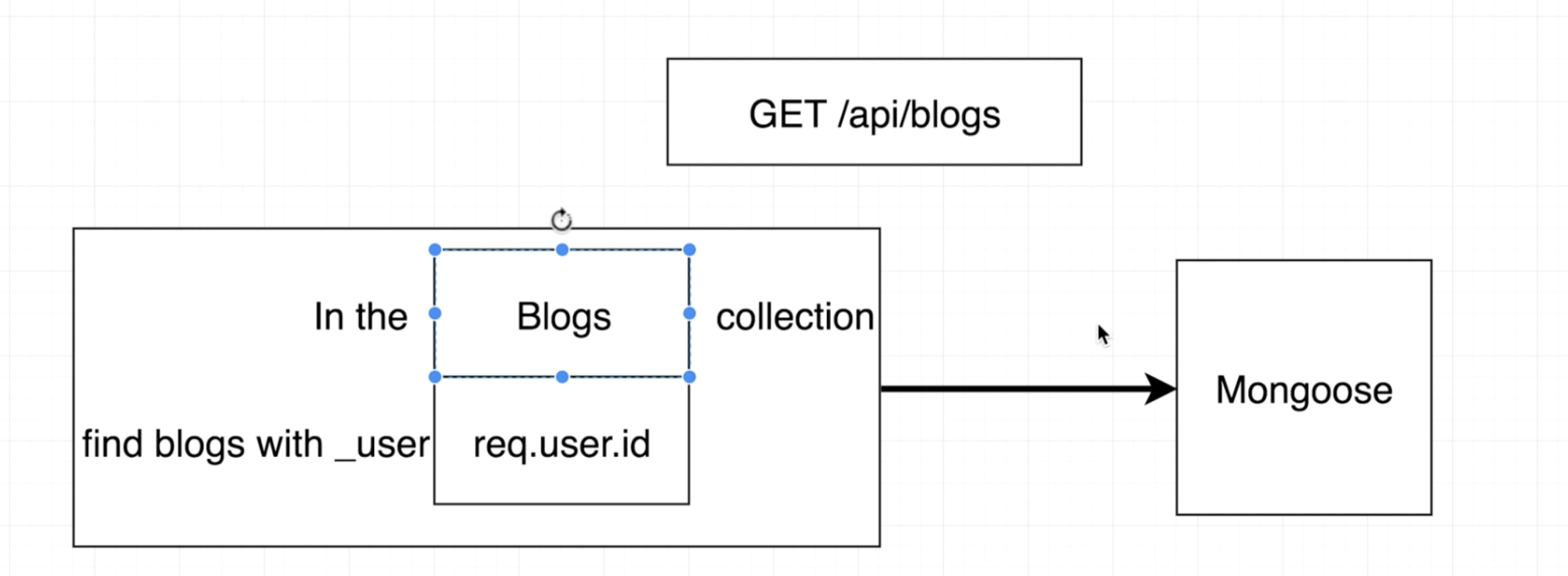

위 요청에 대해서 Caching의 Key 값은 req.user.id가 되는 것이다.
Caching in Action
const redis = require('redis');
const redisUrl = 'redis://127.0.0.1:6379';
const redisClient = redis.createClient(redisUrl);
redisClient.flushall()
JavaScript
복사
위 코드를 통해 redis Instance 내의 모든 데이터를 날려버릴 수 있다.
Caching Issues
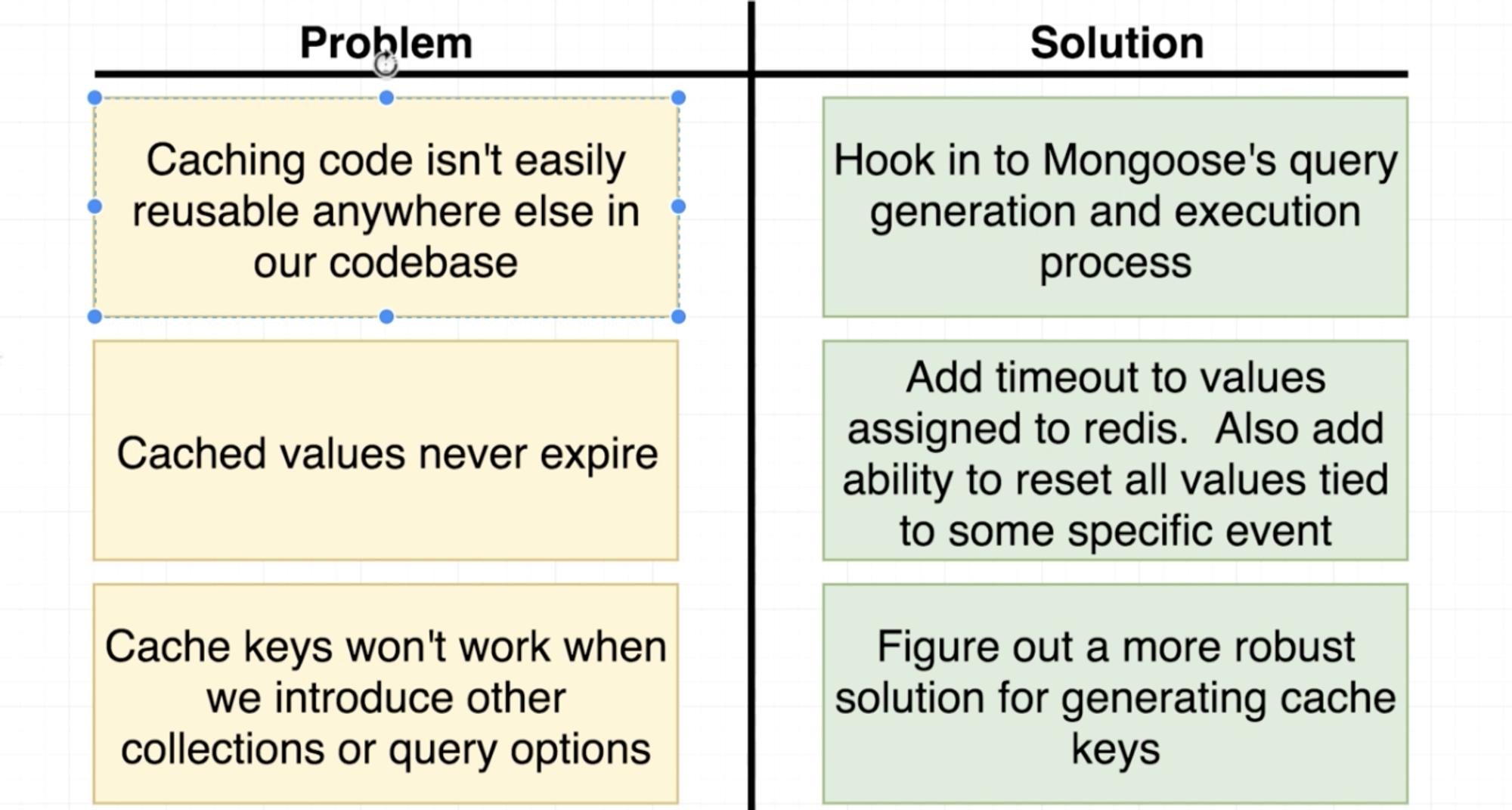
Redis를 통한 Caching을 이용할 때, 위처럼 읽어오기만 할 때는 큰 문제가 없었다. 하지만 블로그 글들을 일종의 state라 했을 때, 게시글을 추가하고, 수정하고, 삭제를 한 경우 새로운 state에 대해서 Redis는 반영하지 않고 여전히 이전 state에 머물러 있는 것은 문제이다. (Caching에는 반영이 되지 않아 원하는 작업이 수행되지 않고 이전 state를 계속해서 보게 된다.) 이는 일종의 Redis 데이터의 만료 기간이 설정 되어 있지 않아서 그렇다.
또한 한 route path 요청 내에
const redis = require('redis');
const redisUrl = 'redis://127.0.0.1:6379';
const redisClient = redis.createClient(redisUrl);
// 해당 Query가 Redis에 Caching되어 있는지 확인
// // const cachedBlogs = client.get(req.user.id, () => {});
// // 위 구문은 바람직 하지 않음 Promisify가 필요
redisClient.get = util.promisify(redisClient.get);
const cachedBlogs = await redisClient.get(req.user.id);
// Caching되어 있다면, Redis로부터 즉시 응답 수신
// JSON.parse
if (cachedBlogs) {
console.log('Serving FROM REDIS');
return res.send(JSON.parse(cachedBlogs));
}
// Caching되어 있지 않다면, Query를 DB로 직접 송신
// Redis Caching 데이터 생성 필요
// JSON.stringify
const blogs = await Blog.find({ _user: req.user.id });
console.log('Serving FROM MONGO');
res.send(blogs);
redisClient.set(req.user.id, JSON.stringify(blogs));
JavaScript
복사
꽤나 반복되는 로직들이 많다.
(일단 1개의 route path 내에 instance를 매 Request 마다 생성하는 것도 그렇고, Caching Key로 찾는 코드들과 json.parse, json.stringify와 같은 반복 되는 코드들이 매 route path 마다 들어가는 것이 조금 그렇다.)
마지막으로, 현재는 user-blog의 관계라서 상관이 없겠지만, 만일 user를 이용하는 모델이 blog에서 몇 가지가 더 추가된다면 현재 코드를 모드 다 일일이 고쳐야 하지 않겠는가. (user로 blog를 찾으려고 했더니 tweet이 나오든가, tweet을 찾으려고 했더니 blog가 나온다든가 말이다.)
과연 이 3가지 문제를 어떻게 고칠 수 있을까?
The Ultimate Caching Solution
Patching Mongoose's Exec
Mongoose에서의 Query라는 타입은 생성자 함수 function Query() {}와 new 키워드를 통해서 만들어 낼 수 있는 객체이다.
해당 객체 내에는 function Query() {}내에 있는 멤버 함수들인 prototype.find, prototype.limit, prototype.exec 등이 있다.
Mongoose Query의 Exec Method를 덮어 쓰기 위해선 멤버 함수인 prototype.exec을 유심히 살펴봐야 한다. 또한 exec 함수가 항상 Promise를 리턴하는 것을 잊으면 안 된다.
const mongoose = require('mongoose');
const exec = mongoose.Query.prototype.exec;
mongoose.Query.prototype.exec = function () {
console.log('hi');
return exec.apply(this, arguments);
};
JavaScript
복사
다음과 같이 덮어쓸 수 있다. exec을 덮어쓴 해당 구문을 app.js에서도 사용해야 하므로 mongoose를 connect하기 이전 부분에 require하여 포함시킨다. (mongoose 연결 이전에 exec 함수가 변경되어야 정상적인 이용이 가능하다. 그리고 exec 함수를 덮어쓴 스크립트의 별도 module.export가 없어도 되는 이유는 별도의 호출을 할 것이 아니기 때문이다. 단순히 해당 스크립트를 require 하는 것만으로 exec 함수를 덮어쓰는 부분은 작동하기 때문이다.)
이런 식으로 라이브러리의 함수를 덮어쓰고, 변경 사항을 적용하여 사용하는 것을 라이브러리에 대한 Monkey Patch라고도 부른다.
Unique Keys
Monkey Patch를 통해서 Mongoose의 Query Exec을 덮어씌웠다면, Caching을 위해 Cache Key를 설정해줘야 Redis에 저장이 가능하다.
해당 함수 내에는 this 라는 키워드를 통해서 Query 객체 자체에 접근이 가능한 점을 이용한다.
mongoose.Query.prototype.exec = function() {
console.log(this.getQuery());
console.log(this.mongooseCollection.name);
}
JavaScript
복사
과 같은 작업을 할 수 있고, 이들을 Key를 두는데 이용한다.
3번 문제 해결법으로 제시된 것은 Inner Query로 묶는 것이 Unique하지 않을 수 있기 때문에, getOptions를 통해 Query에 사용되어 있는 Option들을 Stringify하여 조금 더 완강한 값을 Key로 사용하는 것이었다. 하지만 이는 여전히 중복에 대한 문제가 있다. 어떤 Collection인지 명시하지 않았기 때문에 동일한 Option들이 Key로 묶일 수 있다는 것이다.
또한 서로 다른 Query더라도 동일한 Query 수행 결과를 나타낼 수도 있기 때문에 Query에 수행된 Option을 Key로 묶기보다는 수행 결과를 값을 Key로 묶는것이 조금 더 바람직하다.
위 2가지 고려 사항을 반영하면, Inner Query 수행 결과와 Collection 이름을 함께 Binding한 것을 Cache Key로 사용하면 된다.
따라서 다음과 같은 형태가 될 것이다.
2개의 바인딩 값은 Object라는 객체에 assign이라는 함수를 Chaining하여 만들어 낼 수 있다.
const key = Object.assign(
{},
this.getQuery,
{collection: this.mongooseCollection.name},
);
JavaScript
복사
이렇게 할당된 Key는 Consistent한 결과 값을 나타내면서 동시에 Unique한 값을 갖는다. 앞으로 이렇게 사용할 Key들을 JSON.stringify하여 넘기고, Retrieve할 때도 JSON.parse를 통해서 받는다.
Hydrating Models
mongoose.Query.prototype.exec = async function () {
// caching on redis here
// Cache Key로 활용
// console.log(this.getQuery());
// console.log(this.mongooseCollection.name);
// JSON.stringify 필요
const key = JSON.stringify(
Object.assign({}, this.getQuery(), {
collection: this.mongooseCollection.name,
})
);
// REDIS에 Key가 있는지 확인 후, 있으면 Value 리턴
const cacheValue = await redisClient.get(key);
if (cacheValue) {
return JSON.parse(cacheValue);
}
// 없다면 Query 수행하고 해당 값을 REDIS에 저장
const result = await exec.apply(this, arguments);
redisClient.set(key, JSON.stringify(result));
return result;
};
JavaScript
복사
위와 같이 Caching을 잘한 것 같은데도, 정상적으로 기능들이 작동하지 않는다. 이유가 무엇일까?
Cache Table 내에 들어 있는 값들은 result이다. result는 무엇일까? result는 단순 Object가 아니라 (여기서는 Mongoose를 사용하고 있기 때문에) Mongoose Document이다. 따라서 Caching 이전에 DB를 이용하는 경우에는 Mongoose Document가 리턴되어 정상적인 표시가 되지만, JSON.stringify를 하고 JSON.parse를 하게 되면 result로 리턴 받는 값은 Mongoose Document가 아닌 Plain JSON Data가 된다. Mongoose에서는 exec의 결과로 Mongoose Document를 받아야 하는데 그렇지 않아서 정상적인 작동을 하지 않은 것이다. (Mongoose는 Mongoose Document로 Query 결과를 받으면 Mongoose Document 객체의 멤버 함수를 통해 내부적으로 후처리를 하는 것 같다. 그런데 Plain JSON은 해당 멤버 함수들이 없으니 후처리를 못하는 것이고 따라서 원하는 대로 작동하지 않는 것이다.)
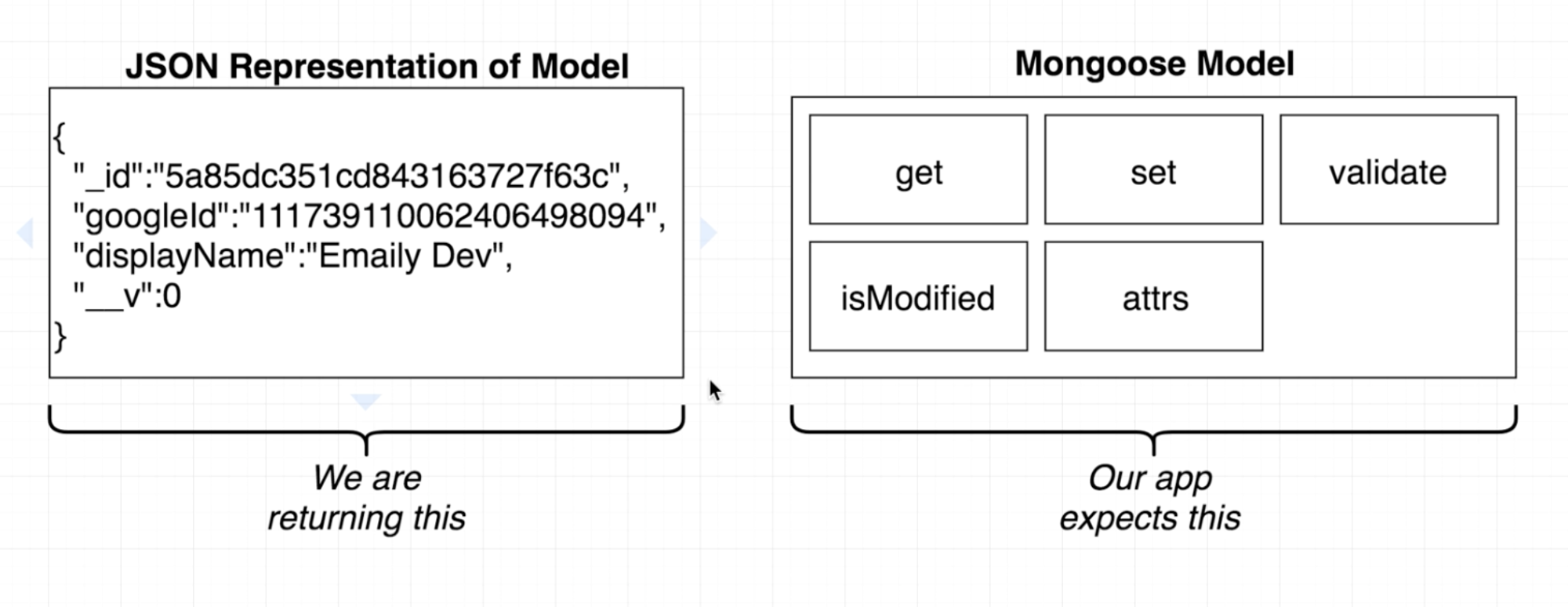
이를 해결하기 위해 this를 찾아보자.
Query Exec 함수 내에서 this를 console.log 해보면 Query 자체에 대해서 자세히 볼 수 있는데, 그 중에서도 Model 부분을 찾을 수 있다. 이 Model을 잘 이용해야 한다.
Query에 사용된 Model은 Mongoose의 Model이고, Mongoose에서 사용해야 하는 여러 멤버 함수들이 포함되어 있다. (애초에 Query 실행 결과로 return 받는 것이 Mongoose Collection 내에 존재하는 Model을 리턴 받으니, 우리가 이용하려고 했던 Mongoose Document가 곧 Model이라 볼 수 있다.) 따라서 Redis로 부터 찾아낸 Value 부분이 Model의 데이터 부분이 되기 때문에, 데이터를 이용하여 new 키워드를 이용하여 새로운 Model 객체를 만들어 낸다.
mongoose.Query.prototype.exec = async function () {
// caching on redis here
// Cache Key로 활용
// console.log(this.getQuery());
// console.log(this.mongooseCollection.name);
// JSON.stringify 필요
const key = JSON.stringify(
Object.assign({}, this.getQuery(), {
collection: this.mongooseCollection.name,
})
);
// REDIS에 Key가 있는지 확인 후, 있으면 Value 리턴
const cacheValue = await redisClient.get(key);
if (cacheValue) {
const doc = new this.model(JSON.parse(cacheValue));
return doc;
}
// 없다면 Query 수행하고 해당 값을 REDIS에 저장
const result = await exec.apply(this, arguments);
redisClient.set(key, JSON.stringify(result));
return result;
};
JavaScript
복사
위와 같이 new 키워드를 통해서 새로운 Model 객체를 만들 때, Cache에서 뽑아낸 정보를 JSON.parse 한 뒤 바로 사용하면 정상적으로 Model이 만들어지지 않는 경우가 있다. new this.model()의 인자로 올 수 있는 것은 1개의 Record 혹은 Object 인데, JSON.parse를 통해 retrieve한 데이터는 Array 일 수도 Object 일 수도 있기 때문이다. (Cache에 존재하는 데이터는 DB에서 찾은 값을 JSON.stringify 해놓은 것인데, DB에서 찾은 값은 1개의 Object일 수도 있고, 여러 Object를 찾은 Array 일 수도 있기 때문이다.)
따라서 Model을 생성하여 return 하는 과정 중에 JSON.parse한 값이 Array라면 이를 Single Object로 바꾼 값을 넣어주면 해결이 된다.
Hash를 통한 Nested Data Structure를 이용하지 않은 Caching은 아래 코드와 같다.
const util = require('util');
const mongoose = require('mongoose');
const redis = require('redis');
const redisUrl = 'redis://127.0.0.1:6379';
const redisClient = redis.createClient(redisUrl);
const exec = mongoose.Query.prototype.exec;
redisClient.get = util.promisify(redisClient.get);
mongoose.Query.prototype.exec = async function () {
// caching on redis here
// Cache Key로 활용
// console.log(this.getQuery());
// console.log(this.mongooseCollection.name);
// JSON.stringify 필요
const key = JSON.stringify(
Object.assign({}, this.getQuery(), {
collection: this.mongooseCollection.name,
})
);
// REDIS에 Key가 있는지 확인 후, 있으면 Value 리턴
const cacheValue = await redisClient.get(key);
if (cacheValue) {
const doc = JSON.parse(cacheValue);
return Array.isArray(doc)
? doc.map((d) => {
return new this.model(d);
})
: new this.model(doc);
}
// 없다면 Query 수행하고 해당 값을 REDIS에 저장
const result = await exec.apply(this, arguments);
redisClient.set(key, JSON.stringify(result));
return result;
};
JavaScript
복사
Toggleable Cache
위 코드와 같이 Query를 수행하면 모든 Query들을 Caching하게 된다. Redis에서 정보를 갖고 오는 것은 정말 좋지만, Redis에 정보를 저장시키는 것은 꽤나 값 비싼 자원을 들여야 한다.
따라서 매 Query마다 Caching을 하는 것이 아니라 Query 코드에 Cache 여부를 결정 지을 수 있도록 만들면 좋을 것이다. 예를 들어 .find(), .where()과 같이 Query Option들을 Chaining하듯, .cache()를 Chaining하면 Caching을 하고 그렇지 않으면 바로 Query를 수행시키는 것이다.
Monkey Patch 시킨 Exec 함수 자체에 인자로 받아도 좋겠지만, 기존 Exec과의 함수 형태가 달라질 뿐더러 유지 보수 측면에서 확장성이나 가독성이 그렇게 좋지 않다. (한 함수에 2가지 기능을 하게 되어버린달까..?)
따라서 Query 객체에 cache라는 Option을 새로 생성하고, 해당 Option을 수행하면 this라는 Query 객체에 Caching 여부에 대해서 설정하도록 만드는 것이 좋다.
mongoose.Query.prototype.cache = function () {
this.useCache = true;
return this;
};
JavaScript
복사
또한 cache Option을 거쳤는지 확인하는 부분을 exec 함수 내에 포함시켜야 한다.
if (!this.useCache) {
return exec.apply(this, arguments);
}
JavaScript
복사
이를 통해 .cache로 Chaining을 하면 Caching을 수행하고, 그렇지 않으면 그냥 DB를 이용하도록 한다. 마지막으로 Cache Expiration 문제만 해결하면 된다.
Forced Cache Expiration
// Duration 추가
redisClient.set(key, JSON.stringify(result), 'EX', 10);
JavaScript
복사
Redis Client에 key & value를 저장할 때, 옵션으로 EX라는 String과 Number를 주면 일정 시간이 지났을 때 key & value 쌍이 만료된다.
하지만 이전에 제시된 문제와 같이, state가 변했을 때 cache 데이터에 대해서 flush 해주지 않으면 결국에 만료시간이 될 때까지 계속 이전 state의 값만 불러오게 될 것이다. (그렇다고 fllushall을 해버리면 state와 관련 없는 데이터 뿐 아니라 다른 사용자의 cache도 다 날라가니 주의해야 한다.)
따라서 다른 사용자의 데이터를 건드리지 않는 선에서 강제로 cache를 만료시키는 방법이 필요하다. (모든 상황에서 되는 것은 아니다. 프로젝트 구조가 다르면 안 될 수도 있다.)
방법은 바로 Nested Hash Object (Nested Data Structure)을 이용하여 사용자 별로 사용하고 있는 Cache를 하나의 Bucket으로 묶고, state에 변동이 생기면 해당 사용자의 Bucket만 초기화 하는 것이다.
여기의 예제에서는 기존에 Query를 Key로 두어 Value와 매칭했던 key & value 쌍은 Nested Hash Object에서 Value로 두고 Key는 사용자 아이디로 두는 것이다.
기존 Caching 구현에서 바꿔줘야 하는 것은 2가지이다.
1.
set, get을 hset, hget을 이용하며 Hash Table의 Bucket을 둘 것
2.
Hash Table에서 특정 Bucket을 지우는 함수의 구현 (Nested된 Object에서 특정 Hash Key 값을 갖는 데이터를 지우는 역할을 한다. 다른 스크립트에서 사용되므로 Monkey Patch했던 Exec함수와 달리 module.export 작업이 필요하다.)
이 방법이 모든 상황에서 통하는 전략이 아니라고 한 것은, 어떤 값을 Bucket으로 두는지에 따라 consistent 속성과 unique 속성을 침범 받을 수 있는 상황이 있을 수도 있기 때문이다. 이 예시에서의 Bucket을 만드는 Key는 사용자 id로 두었고 이 때는 아무런 문제도 없지만, 다른 Model의 구조를 갖는 프로젝트에서는 문제가 될 수도 있다. 또한 더욱 더 복잡한 Model의 관계가 얽혀 있는 구조라면 더더욱 Bucket의 Key 값을 consistent하고 unique하게 잡는 것이 어려울 수 있다. (만일 문제가 없다고 생각했는데도 나중에 문제가 발견될 수도 있다.) 또한 Bucket의 내용을 지우는 함수의 구현 역시 Bucket 값을 무엇으로 두는지에 따라 올바른 Bucket 내용 초기화가 가능한지 불가능한지가 갈리기 때문이다. 따라서 Key와 Bucket으로 이용할 Key 설계가 매우 중요하고, 이것들은 프로젝트마다 달라지기 때문에 항상 통하는 전략은 아닌 것이다. (가능하면 이 전략이 통하게끔 설계하는게 좋지 않을까 싶은 생각이 든다.)
1번에 대한 코드는 아래와 같다.
const util = require('util');
const mongoose = require('mongoose');
const redis = require('redis');
const redisUrl = 'redis://127.0.0.1:6379';
const redisClient = redis.createClient(redisUrl);
const exec = mongoose.Query.prototype.exec;
// redisClient.get = util.promisify(redisClient.get);
redisClient.hget = util.promisify(redisClient.hget);
// 만일 Caching을 할 것이라면 인자로 최상위 부분의 Key 값을 받도록 한다.
// Key는 Nested Hash Object 형태지만, Redis에 저장되므로 Numbers, Strings만 가능하다.
// 혹여나 주어지는 Key가 Object일 수 있기 때문에 JSON.stringify 해준다.
// Key가 주어지지 않았을 경우를 대비해 default 값을 지정해준다.
mongoose.Query.prototype.cache = function (options = {}) {
this.useCache = true;
this.hashKey = JSON.stringify(options.key || '');
return this;
};
mongoose.Query.prototype.exec = async function () {
// caching on redis here
// Cache 여부 판별
if (!this.useCache) {
return exec.apply(this, arguments);
}
// Cache Key로 활용
// console.log(this.getQuery());
// console.log(this.mongooseCollection.name);
// JSON.stringify 필요
const key = JSON.stringify(
Object.assign({}, this.getQuery(), {
collection: this.mongooseCollection.name,
})
);
// REDIS에 Key가 있는지 확인 후, 있으면 Value 리턴
// const cacheValue = await redisClient.get(key);
const cacheValue = await redisClient.hget(this.hashKey, key);
if (cacheValue) {
const doc = JSON.parse(cacheValue);
return Array.isArray(doc)
? doc.map((d) => {
return new this.model(d);
})
: new this.model(doc);
}
// 없다면 Query 수행하고 해당 값을 REDIS에 저장
const result = await exec.apply(this, arguments);
// Duration 추가
// redisClient.set(key, JSON.stringify(result), 'EX', 10);
redisClient.hset(this.hashKey, key, JSON.stringify(result), 'EX', 10);
return result;
};
JavaScript
복사
이 때 만일 Blog 글을 Caching하고 싶다면 아래와 같이 이용할 수 있다. 주어진 Key 값은 req.user.id이므로 Bucket은 사용자 아이디 값으로 나뉘게 된다.
const blogs = await Blog
.find({ _user: req.user.id })
.cache({ key: req.user.id,});
JavaScript
복사
2번의 특정 Bucket의 Key & Value 쌍을 날리는 함수는 아래와 같다.
// 어떤 데이터가 저장되어 있든 해쉬 키에 해당하는 Bucket의 모든 데이터를 지운다.
// 이 때 clearHash의 인자로 주어진 인자가 Object일 수 있으므로 JSON.stringify 해준다.
module.exports = {
clearHash(hashKey) {
redisClient.del(JSON.stringify(hashKey));
},
};
JavaScript
복사
위 함수의 호출을 글을 post해주는 Route Path에서 해주면 글을 작성하고 모든 글들을 보여줄 때, cache에 의해 이전 state의 글들을 보여주는 것이 아니라 해당 Bucket의 cache가 모두 clear되어 DB에서 불러오게 되어 새로운 state의 글을 보여준다. (위 Caching하는 부분의 코드를 보면 이 과정에서 다시 Caching이 발생한다.)
이로써 Caching에서의 3가지 문제를 모두 해결하였다. 마지막으로, Caching을 강제로 Clear해주는 것을 유지보수가 잘 되는 쪽으로 수정해보자. (현재는 Controller 내에서 함수 호출을 해주고 있어서 만일 이에 대해서 수정하려면 Controller를 모두 뒤져야 하는 상황이다. 만일 Route Path의 Middleware로써 수행할 수 있게 해주면, 유지보수를 쉽게 할 수 있을 것이다.)
Automated Cache Clearing with Middleware
Route Path를 따라서 처리되는 하나의 어플리케이션 내에서 Middleware를 두는 것은 일반적으로 Route Path의 Request Handler 이전에 실행되도록 두는 것이 일반적이다. (Route Path의 요청을 처리하는 Request Handler는 일반적으로 req, res만 받아서 처리하는 경우도 있기 때문에, 만일 Request Handler 이후에 Middleware를 둬야 한다면 next인자도 받고 Request Handler 내부에서 next 호출도 해줘야 한다.)
하지만 위 예시에서는 블로그 글을 하나 생성한다고 했을 때, 일반적인 Middlware 사용처럼 먼저 Cache Clearing Middleware를 실행하여 데이터를 지우고 블로그 글을 생성하는 것을 원하는 것은 아니다.
위 케이스에서 조금 더 나아가서 생각해보면, Request Handler를 실행한 뒤에 무조건 Cache를 Clear할 필요도 없다. Request Handler에 의해 성공적으로 글을 생성한 경우에는 Cache Clear를 해야하지만, 중간에 Validation Error 같은 것이 터졌을 경우에는 굳이 다음 Middleware 실행으로 Cache를 날릴 필요는 없다. (어차피 기존 state 그대로니까)
그렇다면 어떻게 Cache Clear Middleware를 성공적으로 문제 없이 추가할 수 있을까? 약간의 트릭스러운 방법으로 Request Handler에 next 인자 추가 없이, Request Handler 이전에 Middleware를 둘 수 있도록 해결할 수 있다.
module.exports = async (req ,res ,next) => {
await next();
clearHash(req.user.id);
}
JavaScript
복사
위 형태와 같이 next 호출을 미리 해버리고 이를 await 하는 것이다. 그리고 next() 호출을 통해 Request Handler 처리가 끝나면 작업을 수행할 수 있도록 await 아래에 Cach Clear 로직을 작성하는 것이다. (애초에 Route Path에 여러 Middleware들을 추가하더라도 다음 Middleware를 실행시켜주는 것은 next()함수인데, 위의 경우는 별도의 next() 호출이 이어지지 않으므로 Route Path에서 해당 Middleware 이후에 Request Handler가 있더라도 다시 호출이 되지는 않는다.)