

Subjects
1. ex00 (Scalar conversion)
42.0f와 같이 소수점 뒤에 리터럴 값의 표기가 있을 때 처리가 안 되었던 기존 방법
(slee2 님 예외 케이스 다수 발견 감사합니다)
std::strtod
토글 처리된 글의 타이틀을 보면 알 수 있듯이, 수정 이전 방법에는 1..1...과 같은 케이스를 포함하여 소수점 아래의 리터럴 값의 표기가 있는 경우 정상적인 처리가 되지 않았다. 이를 해결하기 위해 std::atof 혹은 std::strtod를 이용했다.
스트림을 이용한 변환의 한계점을 명확히 볼 수 있고, 왜 C++11 이후에는 스트림 변환 보다는 std::stoi, std::stof, std::stod 등을 이용하는 것이 권장되는지 알 수 있다.
std::atof는 이름과 달리 const char*를 숫자로 변환할 때 double 타입으로 변환하게 된다. std::strtod의 역할도 std::atof와 동일하게 const char*를 double 타입으로 변환하는데, 기능을 비교 했을 때 std::atof보다 상대적으로 더 탄탄하다. 예를 들어 std::atof를 이용했을 때, 변환하려는 값이 double의 표기 범위를 넘어가는 경우에는 Undefined Behavior이다. 반면 std::strtod는 이와 같은 경우에서 HUGE_VAL이 반환되어 정상적으로 이용되도록 구현되어 있고 (errno는 ERANGE로 설정), 특히 std::atof와 달리 char** 인자를 하나 더 받도록 되어 있어서 숫자로 변환되지 않는 위치를 설정하는 것도 가능하다.
try
{
char *ptr = NULL;
*(const_cast<double*>(&_value)) = std::strtod(_input.c_str(), &ptr);
if (_value == 0.0 && (_input[0] != '-' && _input[0] != '+' && !std::isdigit(_input[0])))
throw (std::bad_alloc());
if (*ptr && std::strcmp(ptr, "f"))
throw (std::bad_alloc());
}
catch (std::exception&)
{
_e = true;
}
C++
복사
따라서 std::strtod를 이용하여 double 타입으로 값을 변환할 때 위치 표기용 char*의 주소값을 넘겨서 변환하면 리터럴 값의 표기 및 원하지 않는 값에 대한 검증이 가능하다. 해당 주소를 역참조 했을 때 정상 변환이라면 '\0'을 얻을 수 있고 그렇지 않으면 '\0'외의 다른 값을 얻게 될 것이다. 특히 후자의 경우에 순수하게 f로 나타나지 않는다면, 변환이 정상적이지 않다는 처리를 해주면 되겠다. 내 경우에는 std::bad_alloc을 던져서 Exception을 마킹하고, 출력 시에 마킹 값을 활용하도록 만들었다.
정상 변환인 경우엔 숫자 이후의 값은 문자열의 가장 끝 값인 '\0'이므로 char*를 역참조하여 그 값을 얻어낼 수 있다.
std::isnan & std::isinf
정상적으로 double 값을 추출했다면 char, int, float, double로 형 변환이 가능한데, 문제에서 요구하는 출력을 위해선 그 값이 nan인지 inf인지도 구분할 필요가 있다. 이는 <cmath>의 std::isnan, std::isinf를 이용하여 알아낼 수 있다.
cpprefence 혹은 cplusplus에서 검색해보면 두 함수가 C++11인 것을 볼 수 있는데, C99 버전의 isnan과 isinf가 <cmath>에도 존재합니다. 두 함수는 모두 매크로 함수를 호출하는 함수이고, C99 버전의 <cmath>는 C++98에 완전한 호환성을 가집니다. 아래 링크들을 통해 isnan, isinf에 대한 정보 그리고 호환성의 레퍼런스를 확인할 수 있습니다. 어렴풋이 경험적으로만 알고 있던 것이었는데, 실제 레퍼런스 체크를 할 수 있도록 도와주신 gshim님께 감사드립니다.

std::showpos & std::numeric_limits<T>::digits10
문제에서 inf에 대해서 명확한 부호를 뽑도록 되어 있는데, 이는 <iomanip>의 std::showpos를 std::cout으로 출력하려는 값 이전에 넣고 출력하면 +, - 부호를 볼 수 있다. std::cout의 기본 설정은 std::noshowpos이므로 별도의 설정이 반드시 필요하다.
간혹 매우 큰 수에 매우 긴 소수점을 넣으면 그 값이 잘려서 표현되는 경우가 있는데, 이는 std::stringstream으로 값을 잘못 찾아낸 것이 아니라 단순히 std::cout의 출력에 대한 precision 설정 때문에 그런 것이다. 따라서 std::setprecision 함수를 std::cout으로 출력하려는 값 이전에 넣고 출력하면, 정해진 precision으로 값을 출력하는 것을 볼 수 있다. 단, 설정된 precision이 표현할 수 있는 precision보다 높다면, 원본 값의 precision을 잃으면서 설정된 precision을 최대한 맞춰서 표현하려고 한다. 이 때문에 precision을 잃지 않게 표현할 수 있는 최대의 precision을 유지하면서 값을 출력할 수 있도록, std::cout과 출력하려는 값 사이에 std::numeric_limits<T>::digits10을 작성했다.
std::numeric_limits<T>는 <limits>에서 사용할 수 있다.
2. ex01 (Serialization)
Only Semantic !
Serialization이라는 용어 때문에 많이 헷갈리는 것 같은데, 문제를 단순화해서 볼 필요가 있다. 이 문제에서 요구하는 것은 사용자가 직접 정의한 임의의 클래스 혹은 구조체인 Data의 포인터를 uintptr_t로 변환하고, uintptr_t를 다시 Data의 포인터로 변환하는 것이다. 이 과정에서 누락되는 데이터가 없는지 확인해야 하고, 데이터들은 온전히 유지되어야 한다.
이와 같은 A→B, B→A의 변환의 의미가 곧 Serialization의 핵심이므로, ex01의 이름이 Serialization이라고 보면 된다.
uintptr_t
uintptr_t는 부호 없는 숫자 타입의 별칭이다. 내 경우에는 uintptr_t는 unsigned long으로 되어 있다. 부호 있는 숫자 타입의 별칭으론 intptr_t가 있으며, uintptr_t와 intptr_t는 포인터가 참조하는 주소를 숫자로 저장하기 위해 이용된다는 점이 동일하다. 일부 시스템에서는 intptr_t가 signed, unsigned의 할당이 모두 가능한 것에 비해, uintptr_t은 unsigned의 할당만 가능하고 signed에 대해서 별도의 타입 변환이 필요한 것을 볼 수 있다. 이 때문에 프로그램의 유연성을 위해 uintptr_t보다는 intptr_t를 이용하는 것이 C 언어 때부터 권장되어 왔다.
ex01은 uintptr_t의 유연성 문제의 상징성 때문에 intptr_t가 아닌 uintptr_t를 사용하지 않았나 조심스레 추측해본다.
#include <cstdint>
#include <iostream>
int main(void)
{
int n1;
unsigned int n2;
uintptr_t p;
p = reinterpret_cast<uintptr_t>(&n1); // p = &n1 -> error
std::cout << &n1 << std::endl;
std::cout << std::hex << p << std::endl;
p = reinterpret_cast<uintptr_t>(&n2); // p = &n2 -> error
std::cout << &n2 << std::endl;
std::cout << std::hex << p << std::endl;
return (0);
}
C++
복사
하지만 C++에서는 포인터에 대한 (포인터 → 포인터, 값 → 포인터, 포인터 → 값) 변환이 필요한 경우에는 모두 별도의 형 변환을 명시해줘야 이용할 수 있다. 포인터에 대한 형 변환은 reinterpret_cast<T>로 유도할 수 있으며, 그 사용 방법은 위와 같다. uintptr_t로 출력된 값을 std::hex를 이용하여 16 진수로 뽑아보면, 원래 각 값이 저장된 주소와 동일한 것을 확인할 수 있다.
따라서 이를 적절히 활용하여 Data* → uintptr_t 그리고 uintptr_t → Data *를 Serialize, Deserialize로 만들어보고, 두 함수의 수행 결과가 초기 상태의 Data와 동일한지 확인하면 된다.
Serialization in Real
아마 이 과제를 진행하면서 Serialization의 의미가 크게 와닿지 않는 사람들도 있을 것이다. 따라서 이 부분을 간단하게 짚고 넘어가보려 한다.
Serialization은 일반적으로 4계층의 TCP, UDP와 크게 관련이 있으며, 특히 Socket 통신과 큰 관련이 있다. 기본적으로 TCP, UDP 통신은 Process-to-Prcoess의 관계에서 이뤄진다. 3계층까지 거쳐 End-to-End의 구분을 통해 어느 Machine으로 가야하는지 판별이 되어 자신에게 해당하는 Packet을 모두 받고 나면, 이를 적절히 자신의 Process들에게 나눠줘야 하고 이것이 4계층의 주된 역할이다. Process에 대한 구분은 OS 단위에서 Port를 이용하여 이뤄지고, 각 Process들이 넘기려는 데이터들은 Port에 종속된 Socket Buffer에 기록하여 OS가 적절히 처리하여 다른 Process 혹은 다른 Machine으로 보내게 된다. (이를 OS Delegation이라 한다.) 이 때, Socket Buffer에 기록하려는 내용 중에 포인터로 참조하고 있는 주소가 기록된다면 어떻게 될까? 다른 Machine은 현재 사용자의 메모리 주소에 대해 알 길이 없기 때문에, 해당 데이터는 해석이 불가능하게 된다. 운이 좋아서 동일 Machine의 다른 Process로 간다고 해도, 이는 재배치 주소이므로 다른 Process에서는 이를 알아보기가 힘들다. 따라서 포인터에 대해선 별도의 변환이 필요하다. 이를 Serialization이라 한다.
위에서 요구되는 기본 개념들은 netwhat에 정리해두었으니, Basic Concept과 4계층에 대한 내용을 먼저 간단히라도 읽고 오면 이해가 조금 더 빠를 것이다.


예를 들어, Data라는 구조체에 100이라는 숫자를 갖고 있고, 해당 값의 주소가 0x10이라고 해보자. 만일 Serialization 없이 Data 구조체를 그대로 기록해버리면, 이를 받는 입장에서는 0x10만 받기 때문에 올바른 값을 받지 못하게 된다. 따라서 Data 구조체가 가진 값을 올바르게 해석시키기 위해선, 0x10을 기록하는 것이 아니라 이를 역참조하여 100이라는 값을 써야 된다. 물론 실제 Serialization은 이와 같이 단순한 포인터 → 값 변환이 아니라, 객체 간 상속 여부, 객체 내 포인터의 순환 여부 등 다른 상황들도 고려되어야 한다. 이처럼 Serialization을 실제로 만들어 내기 위해선 정말 많은 개념들이 포함되는데, 모든 내용들을 이번 서브젝트에 구현하는 것은 불가능에 가까울 뿐만 아니라 범주도 벗어난다. 따라서 ex01에서 요구하는 Serialization은 그 의미만 이용되었다는 점을 이해하고, 단순히 현재 Process에 대해서만 적용될 수 있는 간단한 코드를 통해 reinterpret_cast<T>를 이해하는 것을 목표로 하면 된다.
위에서 언급한 부분들이 적용되면, Serialization은 크게 5가지로 나뉜다. 이에 대해선 아래 글을 참고하자.
3. ex02 (Identify real type)
dynamic_cast<T>?
상속 구조를 만들어 업 캐스팅 후, 자신의 타입이 무엇인지 밝히는 것이 ex02의 목표이다. 우선 범용적인 타입을 확인하는 과정은 여기서 사용하는 방식과 사뭇 다르지만, 상속 구조에서 다형성을 갖는 객체들의 Identification은 dynamic_cast<T>를 이용할 수 있다. 일전에 Module 03에서 직접적으로 다운 캐스팅을 언급하여 dynamic_cast<T>를 보였고, 그 이후에도 종종 dynamic_cast를 이용했다. 여기서는 어떻게 포인터에 대해서 자신의 타입을 인식할 수 있을지, 참조자에 대해서 자신의 타입을 인식할 수 있는지에 대해서 이해할 수 있게, dynamic_cast<T>에 대해 세세히 알아볼 것이다.
기본적으로 static이라는 의미는 컴파일 타임에 파악이 가능하다라는 의미고, dynamic이라는 의미는 런 타임이 되어서야 파악이 가능하다 정도로 이해할 수 있을 것이다. dynamic_cast<T>의 dynamic도 이 의미를 크게 벗어나지 않는다.
RTTI (Runtime Type Information) on dynamic_cast<T>
#include <iostream>
class A
{
std::string s;
public:
A(void)
: s("Base") {}
void text(void)
{
std::cout << s << std::endl;
}
};
class B : public A
{
std::string s;
public:
B(void)
: A(), s("Derived") {}
void text(void)
{
std::cout << s << std::endl;
}
};
int main(void)
{
B b;
A* a_ptr = &b;
B* b_ptr = a_ptr;
b_ptr->text();
return (0);
}
C++
복사

상속 구조를 갖는 객체들 간에는 기반 클래스를 메모리 상에 갖고 있기 때문에 파생 클래스를 기반 클래스의 포인터로 참조하는 것이 가능했고, 따라서 업 캐스팅 시에는 아무런 문제가 없었다. 하지만 파생 클래스가 업 캐스팅 된 기반 클래스 형태가 아니라 순수한 기반 클래스를 이용하는 경우라면, 파생 클래스를 메모리 상에 유지하고 있지 않기 때문에 파생 클래스로의 다운 캐스팅은 문제가 될 수 있다. 이 때문에 기본적으로 컴파일러는 다운 캐스팅을 금지하고, 이와 같은 시도를 하면 에러를 내준다.
#include <iostream>
class A
{
std::string s;
public:
A(void)
: s("Base") {}
void text(void)
{
std::cout << s << std::endl;
}
};
class B : public A
{
std::string s;
public:
B(void)
: A(), s("Derived") {}
void text(void)
{
std::cout << s << std::endl;
}
};
int main(void)
{
B b;
A* a_ptr = &b;
B* b_ptr = static_cast<B*>(a_ptr);
b_ptr->text();
return (0);
}
C++
복사

그런데 파생 클래스 → 기반 클래스 → 파생 클래스로의 캐스팅은 문제가 없지 않은가? 따라서 해당 경우에는 기반 클래스를 파생 클래스로 변환하는 것이 가능해야 하는데, 컴파일러에게 기반 클래스를 파생 클래스로 인식시키도록 static_cast<T>를 이용할 수도 있지 않은가? 맞는 말이다. static_cast<T>를 이용하여 기반 클래스를 파생 클래스로 인식시키면, 컴파일도 되고 실행도 잘 되는 것을 확인할 수 있다.
#include <iostream>
class A
{
std::string s;
public:
A(void)
: s("Base") {}
void text(void)
{
std::cout << s << std::endl;
}
};
class B : public A
{
std::string s;
public:
B(void)
: A(), s("Derived") {}
void text(void)
{
std::cout << s << std::endl;
}
};
int main(void)
{
A a;
A* a_ptr = &a;
B* b_ptr = static_cast<B*>(a_ptr);
b_ptr->text();
return (0);
}
C++
복사

하지만 이와 같은 static_cast<T>의 이용은 파생 클래스 → 기반 클래스 → 파생 클래스 뿐만 아니라 기반 클래스 → 파생 클래스에 대해서도 에러를 만들지 않기 때문에, 위와 같이 기반 클래스 → 파생 클래스는 실행이 되어서야 런 타임 에러가 나는 것을 확인할 수 있다. 즉, 사전에 컴파일 타임에서 에러를 찾아낼 수 없기 때문에 실제 상황에서는 꽤나 머리가 아픈 상황을 맞을 수도 있다.
#include <iostream>
class A
{
std::string s;
public:
A(void)
: s("Base") {}
void text(void)
{
std::cout << s << std::endl;
}
};
class B : public A
{
std::string s;
public:
B(void)
: A(), s("Derived") {}
void text(void)
{
std::cout << s << std::endl;
}
};
int main(void)
{
A a;
A* a_ptr = &a;
B* b_ptr = dynamic_cast<B*>(a_ptr);
b_ptr->text();
return (0);
}
C++
복사

따라서 이처럼 파생 클래스 → 기반 클래스 → 파생 클래스에 대해선 허용하면서도, 기반 클래스 → 파생 클래스에 대해서는 막을 수 있는 방법이 필요한데, 이 때 이용되는 것이 dynamic_cast<T>이다. dynamic_cast<T>를 이용하면 위처럼 기반 클래스 → 파생 클래스에 대해서 컴파일 타임에 에러를 내는 것을 확인할 수 있다. 그렇다면 만일 A 클래스의 text 함수에 virtual 키워드가 붙은 경우에는 어떻게 동작하게 될 까? 이는 static_cast<T>와 dynamic_cast<T>의 특성으로 이해할 수 있다.
static_cast<T>는 B 클래스의 포인터로 할당을 위해 A 클래스의 포인터를 일시적으로 형 변환한 것이므로, B 클래스의 포인터가 참조하는 공간은 여전히 A 클래스 타입으로 이해된다. 따라서 text를 호출했을 때는 vTable에서 실제 타입인 A 클래스의 text를 호출하게 된다.
반면에 dynamic_cast<T>는 B 클래스의 포인터로 할당을 위해 A 클래스의 포인터를 형 변환하는 과정이 static_cast<T>와는 사뭇 다르다. A 클래스의 포인터로 참조되는 객체가 B 클래스의 포인터로 참조될 수 있는지 먼저 확인하고, 기반 클래스 → 파생 클래스에 해당하므로 변환이 불가능하다는 것을 인지하여 b_ptr에는 NULL이 할당된다. 따라서 NULL의 text를 호출하려 했으므로 SegFault가 발생한다. 이처럼 dynamic_cast<T>는 형 변환 가능 여부를 확인할 수 있도록 되어 있기 때문에, 여러 상황에 대해서 대처할 수 있다.
dynamic_cast<T>로 형 변환할 수 없을 때 T가 무엇인지에 따라 반환 값이 다른데, 이는 아래에서 다룬다. 만일 형 변환이 가능하다면 static_cast<T>에서는 일시적으로 형 변환이 되었던 것과 달리, dynamic_cast<T>의 결과는 인식되는 타입을 아예 바꾸게 만든다.
dynamic_cast<T>이 위와 같이 동작할 수 있는 것은 RTTI (Runtime Type Information)이라는 C++ 컴파일러의 기능 덕분이다. 이름에서 알 수 있듯이, 객체의 유형을 런 타임에 결정할 수 있도록 만드는 것이다. 이와 같은 기능은 객체가 위치한 메모리 상에 객체 타입에 대한 정보를 추가하면서, 실제 타입을 이용하지 않고 제공된 타입을 이용하면서 이뤄질 수 있다. 따라서 dynamic_cast<T>를 이용하면 실제로는 A 클래스 타입이지만, 형 변환에 따른 결과는 이와 다를 수 있게 되는 것이다. 결론적으로 업 캐스팅을 제외한 상속 구조의 객체 간의 형 변환 (다운 캐스팅, 크로스 캐스팅)에서는 RTTI를 기반으로 동작하는 dynamic_cast<T>를 쓰는 것이 안전하다.
dynamic_cast<T>의 이용은 업 캐스팅에서도 이용할 수 있지만, 주로 다운 캐스팅 혹은 크로스 캐스트에서 이용된다. 언급된 두 형 변환은 아래 링크에서 자세하게 다뤄져있다.

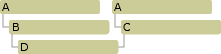
dynamic_cast<void *>
#include <iostream>
class A
{
public:
virtual ~A(void) {}
};
class B : public A
{
};
class C : public A
{
};
class D : public B, public C
{
};
int main(void)
{
D d;
B* b_ptr = &d;
C* c_ptr = &d;
if (dynamic_cast<A*>(b_ptr) == dynamic_cast<A*>(c_ptr))
std::cout << "Same" << std::endl;
else
std::cout<< "Not Same" << std::endl;
return (0);
}
C++
복사

dynamic_cast<T>에서 T를 void*를 주게 되면 조금 특별한 역할을 하게 된다. 상속 구조에서 최하위에 존재하는 파생 클래스를 참조하는 void*로 형 변환하게 된다. 이와 같은 기능을 확인하기 위해 다이아몬드 상속 형태로 클래스들을 정의하였고, 억지스럽긴 하지만 공통 상속 클래스는 virtual로 두지 않았다. D 클래스로 정의된 d 객체는 B 클래스가 되어도, C 클래스가 되어도 두 비교 값은 같아야 하는데, 실행 결과는 그렇지 않은 것을 볼 수 있다.
두 주소의 비교를 위해 B 클래스와 C 클래스를 모두 A 클래스로 업 캐스팅 했다.
#include <iostream>
class A
{
public:
virtual ~A(void) {}
};
class B : public A
{
};
class C : public A
{
};
class D : public B, public C
{
};
int main(void)
{
D d;
B* b_ptr = &d;
C* c_ptr = &d;
if (dynamic_cast<void*>(b_ptr) == dynamic_cast<void*>(c_ptr))
std::cout << "Same" << std::endl;
else
std::cout<< "Not Same" << std::endl;
return (0);
}
C++
복사

따라서 두 주소가 동일하다는 것을 dynamic_cast<void*>를 이용하여 최하위에 존재하는 파생 클래스의 시작 위치를 얻어내어 비교하면, 위 결과처럼 동일하다는 결과를 얻어낼 수 있다.
// dynamic_cast<T>(void*) -> Error
C++
복사
주의할 점으로는 dynamic_cast<void*>는 가능하지만 dynamic_cast<T>를 수행하려는 인자를 void*로 사용하면 안 된다.
Failure on Pointer & Reference on dynamic_cast<T>
// dynamic_cast<T*> -> When Error, NULL returned
// dynamic_cast<T&> -> When Error, Exception throwed
C++
복사
ex02의 dynamic_cast<T>의 결론에 달했다. dynamic_cast<T>의 T로는 포인터가 올 수도 있고, 참조자가 올 수도 있다. dynamic_cast<T>의 형 변환 실패는 기본적으로 NULL을 기반으로 한다고 생각하면 편하다. 포인터의 경우 T*에 대한 NULL은 존재할 수 있으므로 형 변환 실패 시 NULL이 반환되고, 참조자의 경우 NULL에 대한 참조는 불가능하기 때문에 Exception을 던지게 된다.
따라서 dynamic_cast<T>를 이용하여 상속 구조에서 자기 자신의 타입이 무엇인지 알 수 있는 방법은 다음과 같다. T가 포인터로 들어온 경우에는 NULL을 반환하지 않은 경우가 자기 자신의 타입이고, T가 참조자로 들어온 경우에는 Exception이 던져지지 않은 경우가 자기 자신의 타입이다.