


1. 들어가기 전에
많은 사람들이 C 언어를 배우면서 동적할당이라는 것을 배우다 보면 Heap이라는 메모리 영역에 대해서 듣게 되고, 이에 따라 프로세스를 실행했을 때 할당되는 메모리 구조를 배우게 될 것이다.
나는 C 언어를 처음 배우면서 Heap이라는 것을 처음 들었었고, 3학년 때 운영체제를 수강하기 전까지는 메모리 구조에 대해서 크게 신경 쓰지 않았다. 3학년 때 운영체제를 배우고 나서야 프로세스가 구동되면서 각 Segment 별 역할이 어떻게 되는지 조금 더 자세히 알게 되었고, 이후로 코딩할 때는 한 번씩 메모리 구조가 생각나곤 했었다.
학부 운영체제를 수강하고 기억에 남는 것은 프로세스에 할당되는 메모리는 크게 4가지 구조로 이뤄진다는 점이었다. 낮은 메모리 주소부터 높은 메모리 주소 순서로 했을 때, Code Segment, Data Segment, Heap, Stack으로 나뉜다고 알고 있었다. 그리고 각 Segment 별로 Code Segment는 프로그래밍을 한 Code들이 들어있고 (어렴풋이 함수는 실행이 되지 않아도 주소 값 자체는 갖고 있다는 것을 들은적이 있었는데, Code Segment를 배우면서 함수들의 주소 값들이 여기에 있고 함수 호출 시 Code Segment로 함수를 찾으러 오겠구나 라고 생각했던 기억이 있다.), Data Segment는 전역 변수와 정적 변수가 저장되는 곳, Heap은 동적으로 크기가 바인딩 되어 사용 되는 공간, Stack은 지역 변수와 같이 정적 바인딩이 되어 사용되는 공간 정도로만 알고 있었다.
하지만 C 언어를 다시 공부하면서 메모리 구조에 대해서 조금 더 자세히 찾아보게 되었고, 오늘은 프로세스에게 할당되는 메모리 구조에 대해서 살펴보려 한다.
2. Stack과 Heap
Stack은 지역 변수들을 저장하는데 이용된다. 지역 변수들은 블록 내에서만 동작하도록 Scope가 존재하고, Scope가 다른 곳에서는 동일한 변수 이름을 이용할 수 있다. Scope 내에 있을 때는 Stack 내에 살아있게 되지만, Scope 밖으로 나가게 되면 해당 변수는 해제된다. Stack 내에 존재하는 변수들은 모두 컴파일 타임에 크기가 정해져 있지만 변수가 Stack에 할당되었다가 해제되는 과정은 런 타임에 일어난다.
Heap은 Stack과 달리 동적으로 할당된 데이터들이 저장되는 곳이다. 특징으로는 변수 선언과 같이 메모리 자체에 네이밍이 없다는 것이다. 따라서 동적으로 생성된 데이터들은 모두 포인터를 통해서 접근해야 한다. (동적할당에 사용된 포인터 지역 변수들은 모두 Stack에 선언 된다.)
Stack에서 사용한 것과 같이 지역 변수의 선언은 특정 메모리 공간을 변수 이름으로 사용하겠다는 의미인데, 동적할당에서는 그런 것이 불가능하다. 즉, 동적할당에서 생성된 데이터들도 Anonymous이다.
Heap에서 생성된 데이터들은 Stack을 이용한 지역 변수와 달리 그 크기가 컴파일 타임에 정해지는 것이 아니라 런 타임에 정해지게 되고 할당 자체도 런 타임에 일어난다.
Stack의 경우 Scope를 벗어나면 자동으로 변수가 소멸된다고 했지만, Heap은 프로그램이 종료되기 전까지는 메모리를 계속 잡아 먹고 있다. 즉, Heap에 존재하는 데이터들은 모두 Anonymous인데다가 계속 메모리를 먹고 있는 상태므로 자칫 잘못하여 Anonymous한 데이터를 가리키고 있는 포인터가 다른 곳을 가리키게 되면, Anonymous한 데이터에 접근할 수 있는 방법이 사라지기 때문에 프로그램이 종료되기 전까지 메모리 해제가 불가능하다. 이런 현상을 메모리 누수라고 부른다.
일반적으로 Heap의 크기와 Stack 크기는 운영체제, 컴파일러 등 환경에 따라 기본적으로 할당되는 크기가 각각 다르다. 하지만 대체적으로 Heap의 크기는 Stack의 크기보다 압도적으로 크다.
1) Stack과 Heap의 구분
우리는 코드를 작성할 때 Stack Overflow와 메모리 누수에 대해 고려하면서 코딩을 하게 되지만, 코드를 작성하는 순간에는 C 언어 자체적으로 Stack과 Heap을 나누지 않는다. 그렇다면 내가 작성한 프로그램에 대해서 Stack과 Heap을 구분 짓는 때는 언제일까? 잘 생각해보면 작성한 코드에 대해서 Stack Overflow라든가 메모리 누수와 같은 오류는 프로그램을 실행했을 때 볼 수 있었다.
코드를 작성하여 컴파일을 하고 목적 파일들을 연결하여 실행 파일을 만들었다고 생각해보자. 프로그램을 운영체제에서 실행하게 되면, 운영체제는 이 프로세스에 Stack과 Heap의 영역을 구분지어 메모리를 할당하게 된다. (프로그램이 RAM에 적재된다.) 이 때 프로세스에 할당된 메모리는 단순히 Stack과 Heap 영역으로만 분류되는 것이 아니라, Code Segment, Data Segment까지 포함하여 크게 네 영역으로 구분된다. 각 영역에 대해서 낮은 주소부터 높은 주소 순서대로 나열해보면 Code Segment, Data Segment, Heap, Stack으로 구성된다. Heap은 낮은 주소에서부터 높은 주소쪽으로 할당되고 Stack은 높은 주소에서부터 낮은 주소쪽으로 할당된다. 우선, 메모리의 각 영역에 대해서 다루기 전에 Heap과 Stack이 서로 반대 방향으로 메모리를 할당하는 이유에 대해서 내 생각을 풀어보고자 한다.
2) Stack과 Heap 메모리 할당 방향이 서로 다른 이유에 대한 고찰
두 가지 측면으로 나눠서 생각을 하게 되었는데, 첫째는 메모리 이용에 대한 효율성이고 둘째는 안정성으로 생각을 했다. 서로 반대 방향으로 크기가 커져 가는 것은 Heap과 Stack 뿐 아니라 데이터 베이스에서 VarChar와 같이 가변 길이의 Record를 저장할 때 사용하는 Slotted Page Structure에서도 찾아 볼 수 있다. (이게 제일 먼저 떠올랐다.)
Slotted Page Structure
Heap과 Stack에 대해서도 Slotted Page Sturcture를 사용하는 것과 동일한 이유로 서로 반대 방향으로 메모리를 할당하는 것이라는 생각이 들었다. (데이터 베이스에 대해서 공부한 것을 적는 시간은 아니지만, 조금의 이해를 돕기 위해 데이터 베이스도 끌어서 설명을 해보겠다.)
데이터 베이스는 테이블들의 모임이라고 볼 수 있고, 테이블들은 튜플(Record와 같은 말)의 모임, 튜플은 속성 값들의 모임이라고 볼 수 있다. 각 테이블들은 튜플 단위로 관리 되는데, 튜플에 해당하는 속성 값들을 저장함으로써 튜플을 저장할 수 있다. 데이터 베이스는 단순히 데이터를 저장하는 기능만 수행하지 않고 데이터를 찾는 기능도 수행하기 때문에 테이블에 접근하여 튜플을 찾아내는 것이 매우 중요하다. 또한 튜플의 속성 전체를 찾아내는 것이 아니라 필요한 속성만 찾아내는 쿼리를 수행하는 것도 허다하기 때문에 한 테이블에서 저장되는 튜플의 크기에 대해서 아는 것과 각 속성 값의 크기를 아는 것은 성능과 직결되기 때문에 굉장히 중요하다. 하지만 속성 값들은 정해진 스키마에 따라서 항상 크기가 일정한 것이 아니라, VarChar 타입을 사용하는 경우에는 속성 값의 크기도 가변적이고 이에 따라 튜플의 크기도 가변적이게 된다.
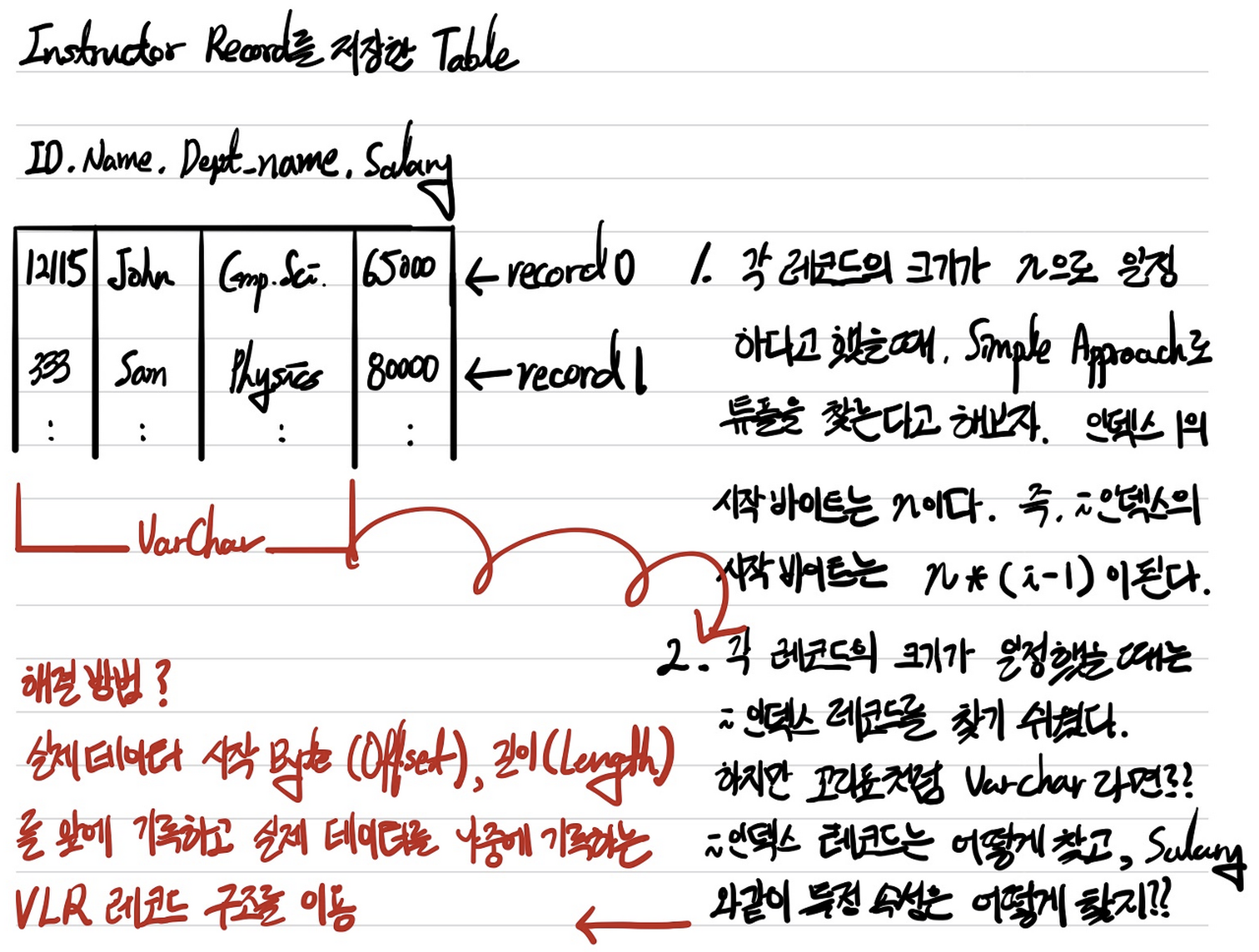
Record 접근 방법
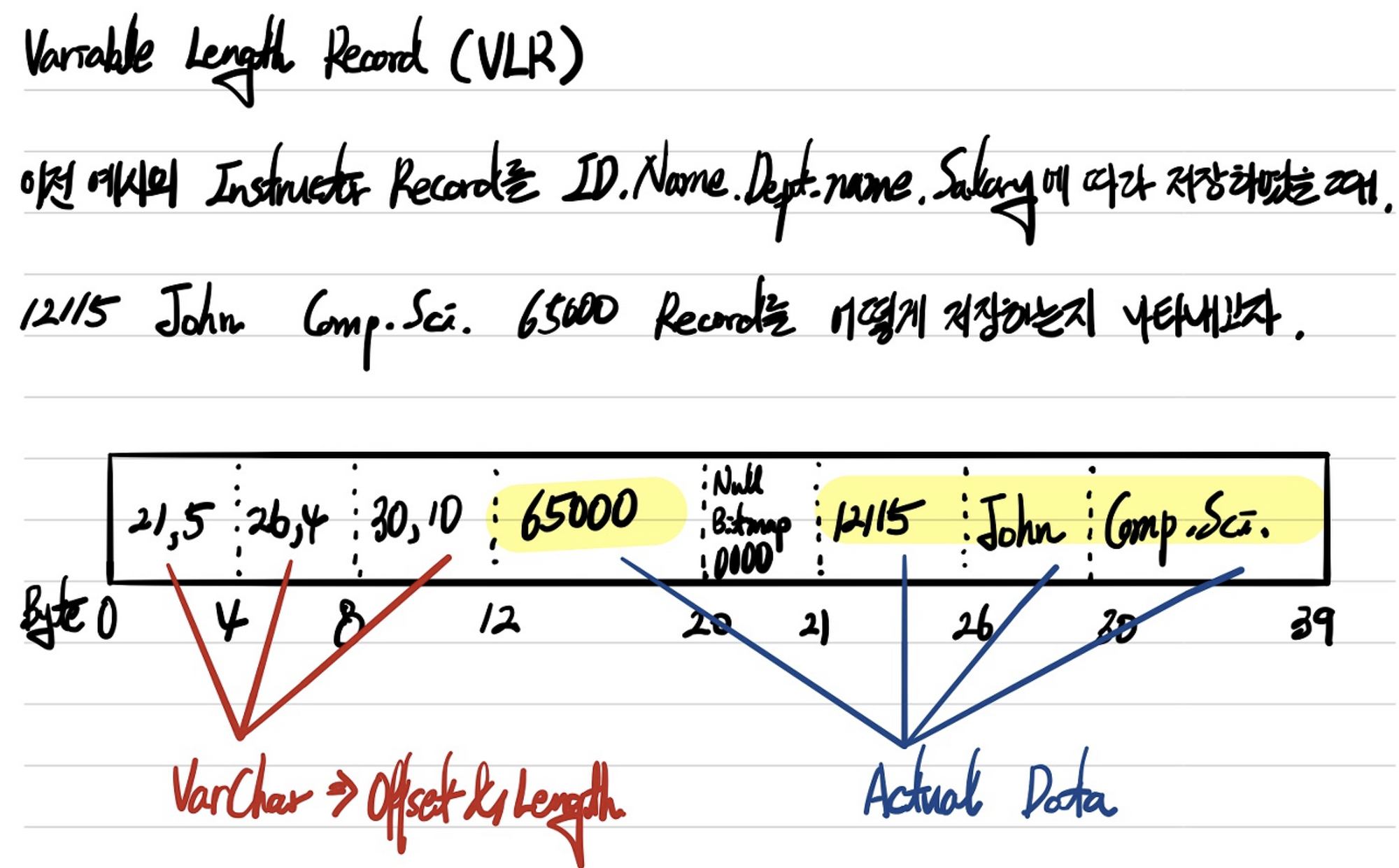
Variable Length Record
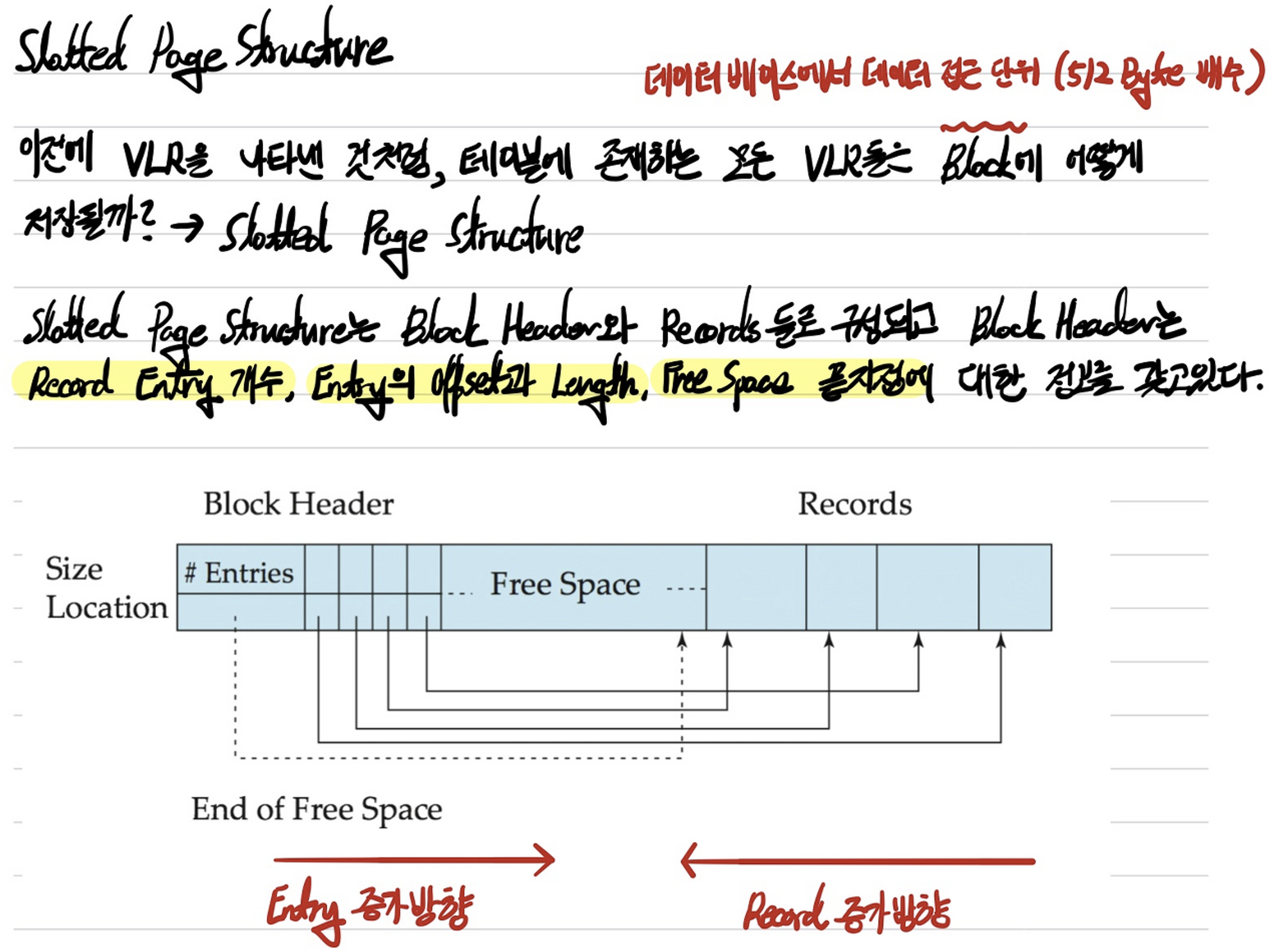
Slotted Page Structure
서론이 길었다. 그래서 Slotted Page Structure에서 Entry의 저장 방향은 앞에서 뒤, Record의 저장 방향은 뒤에서 앞이다. 왜 Entry와 Record 두 개 모두 앞에서 뒤로 저장하는 방식을 두지 않았을까? 우선 둘다 앞에서 뒤로 저장하기 위해선 어느 지점부터 Record를 기록할지 기준이 필요하다. 그리고 둘다 앞에서 뒤로 저장하는 방식을 이용하게 되면 Record의 크기가 Entry의 크기보다 크기 때문에 Block은 꽉 찼는데, (Record 저장 시작 기준을 정했기 때문에) Entry를 저장하는 공간이 남아버리는 사태가 발생할 수 있다. 그렇다면 Record를 저장하는 공간을 더 주면 되지 않는가? 라고 생각할 수 있지만, Record의 크기는 정해진 것이 아니라 어떤 테이블의 Record를 사용하느냐에 따라 크기가 달라지기 때문에 Record 저장 시작 기준을 정한다는 것 자체가 난해하다. 따라서 일반적으로 Block에 VLR을 저장할 때 남는 공간에 대한 비효율성을 해결하기 위해 Record에 대한 기록은 뒤에서부터 하게 된다.
효율성
비록 Stack과 Heap이 VLR과 같은 형태로 저장되는 것도 아니고 Slotted Page Structure처럼 뒤 쪽에서 이용되는 Stack이 Heap보다 큰 용량을 차지하는 형태도 아니지만, Slotted Page Structure의 비슷한 원리로 Heap이 유동적인 크기를 이용하므로 Free Space 이용에 대한 효율성을 높이고자 서로 반대 방향으로 이용하는 것이 아닌가 싶었다. 그리고 Free Space 활용의 효율성 뿐만 아니라, Stack 특성 때문에 Stack만큼은 끝에서부터 이용하여 Heap과 반대 방향으로 이용되는 것이 유리하다는 생각도 들었다.
Stack은 지역 변수를 저장하기 때문에 Stack에 남아 있는 지역 변수를 확인하는 것으로 함수 호출에 대한 추적을 용이하게 한다. 또한 이 과정에서 Scope를 벗어난 지역 변수는 메모리에서 해제된다. 이런 지역 변수 이용에 대한 것은 굉장히 빈번하기 때문에 메모리 중간에 사용하게 되면, 지역 변수를 기록하는 것에도 해제하는 것에도 그 위치까지 타고 가야하므로 불필요한 이동이 많아진다고 생각했다.
여기까지가 Stack과 Heap이 서로 반대 방향으로 이용되는 효율성 쪽으로의 고찰이었다.
안정성
안정성 측면은 바로 프로세스의 Abstraction으로 접근하여, 프로세스 간 Protection을 보장하는 것이라고 생각했다. 우선 구동되고 있는 프로세스가 어떤 식으로 메모리에 올라가는지 차근 차근 확인해보자.
여러 프로세스를 구동하는 상황이라고 했을 때, 프로세스는 해당 프로세스의 크기만큼 RAM에 올라가지 않는다. 만일 RAM의 크기가 8GB인데, 프로세스의 크기가 10GB가 되어버리면 RAM에 적재할 수 없는 상황이 되어버리지 않는가? 또한 용량이 큰 여러 프로세스를 올리면 RAM에 적재할 수 없고, 이는 RAM 용량만큼만 프로세스를 실행할 수 밖에 없다는 것이다. 하지만 실제로 컴퓨터를 이용해보면 알겠지만, 용량이 큰 프로그램을 아무리 많이 실행시켜도 실행 자체는 가능하다. 이것이 가능한 이유는 Virtual Memory를 이용했기 때문이다. 각 프로세스 마다 현재 이용 중인 부분에 대해서 Page를 두고, 프로세스를 Page 단위로 Virtual Memory에 올려 사용하게 된다. Page들은 Page Table에 기록되어 Physical Memory의 어느 주소를 이용하는지 알 수 있게 해준다. Virtual Memory 덕분에 프로세스의 크기가 아무리 크더라도 현재 이용 중인 부분에 대해서만 Page를 올려 사용하기 때문에 아무런 문제가 없는 것이다.
실제로 프로세스를 메모리에 올릴 때 Virtual Memory를 사용하더라도 결국에는 Physical Memory로 매칭되기 때문에, 프로세스들이 비록 Physical Memory에 연속적으로 Linear 적재되지는 않지만 결국에 프로세스들이 Physical Memory에서 맞닿을 수 있는 상황이 충분히 있다. 이 때 Stack이 쌓이는 방향이 낮은 주소에서 높은 주소로 향하게 되면, Overflow가 발생했을 때 다른 프로세스를 침범할 수도 있고 프로세스 간의 Protection을 보장할 수 없게 된다고 생각했다. 하지만 Stack의 방향이 높은 주소에서 낮은 주소로 향하게 되면, 정해진 Stack의 크기를 초과하게 되더라도 다른 프로세스를 침범하지 않을 수 있게 되어 Protection을 보장할 수 있게 되지 않을까라고 생각했다.
3. 메모리 적재 순서
메모리는 크게 4개의 영역으로 나뉜다고 했는데, 위에서 다룬 Stack과 Heap을 제외한 각 영역에 대해서 어떤 것들을 어떤 순서대로 적재하게 되는 것일까?
실행 파일의 모든 코드들이 Code Segment에 가장 먼저 올라가고, 컴파일 타임에 결정되는 Global 및 Static 변수들을 Data Segment에 올리게 된다. 크기가 정적으로 바인딩 되어 있는 지역 변수들은 런 타임에 생성하여 Stack에 두게 되고, 크기가 동적으로 바인딩 되는 동적할당 변수들은 Heap이라는 공간에 지역 변수들과 마찬가지로 런 타임에 할당이 된다. 이렇게 낮은 주소에서부터 높은 주소로 메모리에 할당이 되는데, 크게 네 개로 나눈 영역들은 조금 더 세분화하여 나눌 수 있다.
Code Segment의 경우 Text 영역, Init(Const) 영역, RO Data 영역으로 나눌 수 있다. (Code Segment에 있는 것들은 Read Only만 가능하기 때문에 수정은 불가능하다. 또한 RO이기 때문에 문자열 리터럴에 대해서는 변경의 여지가 있는 char *로는 받을 수 없다. 문자열 리터럴에 대해서 함수의 인자로 받고 싶다면 const char *를 통해서 받아야 한다.)
Data Segment의 경우 Data 영역, BSS 영역으로 나눌 수 있다.
각 영역 별 어떤 값들을 저장하게 되는지 살펴보고, 예시 코드를 통해 프로그램이 실행될 때 메모리에 어느 부분에 적재되는지 알아보자.
1) Code Segment
Text 영역
이전에 알고 있었던 대로, 프로그램을 만들 때 작성했던 코드들이 올라가는 부분이다. 작성한 모든 코드들이 Text 영역에 올라가기 때문에 선언한 함수들 역시 Text 영역에 기록되고 주소 값을 갖게 된다. 실제로 함수를 호출하여 할 때, 호출된 이름을 가진 함수를 Text 영역에서 찾아 이용하게 된다.
Init(Const) 영역
Init 영역에는 상수 값들이 오게 되는데, 여기서 말하는 상수는 초기화에 사용된 상수 값 (리터럴 그 자체)를 의미한다. 여기서 말하는 상수 값이란 const가 붙은 상수화된 변수를 의미하는 것이 아니다.
const int a = 10;
int b = 11;
char *str = "Hello";
C
복사
다음과 같이 나타 났을 때, Init 영역에 할당되는 값들은 a, b, str과 같은 변수를 말하는 것이 아니라 10, 11, "Hello"와 같은 초기화에 사용된 리터럴들이 Init 영역에 할당되는 것이다. 그렇다면 a, b, str은 어디에 할당되는가?
아래 내용들을 읽으면 자세히 알수 있는데, 전역 변수라면 Data 영역에 할당되고 지역 변수라면 Stack에 생성된다. 즉, 변수 자체는 (const가 붙어서 상수화 된 변수들도 포함하여) Code Segment에 할당되는 것이 아니고, 이 변수들에 할당된 상수 값 (리터럴)들이 Code Segment에 할당되는 것이다.
RO Data 영역
RO Data 영역 역시 리터럴들만 차지하는 공간이다. Init(Const) 영역도 리터럴들만 차지하는 공간이었는데, RO Data 영역과의 차이가 어떻게 되는 걸까?
RO Data 영역에 저장되는 리터럴들은 초기화에 사용되지 않은 모든 리터럴들이다.
정리
// 모든 코드들은 Text 영역
int a = 10; // Init 영역
a = 15; // RO Data 영역
void getDiameter(int radius) {
printf("%d", 2 * radius); // RO Data 영역
}
int main() {
getDiameter(200); // RO Data 영역
return 0;
}
C
복사
위 코드의 주석에 기재된 것과 같이 초기화 구문에 이용된 리터럴들을 제외하고, 15, 2, 200과 같은 리터럴들이 RO Data 영역에 들어가게 된다. Init 영역에 쓰인 리터럴들과 RO Data 영역에 사용된 리터럴 모두 다음과 같이 동작한다.
코드를 컴파일 한 후, 실행 파일로 만들게 되면 리터럴들은 Init 영역과 RO Data 영역으로 나뉘어 실행 파일이 실행되기 이전에 분류가 이미 된 상태로 존재한다. 그리고 실행 파일을 구동하게 되어 위 코드들이 한줄 한줄 읽히면, 변수가 있는 메모리 공간에 즉석으로 값이 할당되는 방식이 아니라 해당 리터럴이 존재하는 Init 영역이나 RO Data 영역에 저장되어 있던 값을 찾아서 변수 메모리 공간에 할당하게 되는 것이다.
추가적으로, 15, 2, 200은 문자열 리터럴과 마찬가지로 이름이 없는 상수 값 그 자체이므로 Anonymous라고 부르게 된다. 이름이 없는 익명의 상수 값이기 때문에 포인터를 사용하는 것이 아니고서는 접근이 불가능하다.
Init 영역과 RO Data 영역에 생성된 리터럴 값들은 Read Only이므로 절대 변경될 수 없다.
2) Data Segment
두 영역은 모두 전역으로 사용된 변수가 저장되는 곳이다. 전역으로 사용되지 않더라도 static과 같은 키워드가 붙어서 정적인 변수로 이용한 것들도 모두 두 영역으로 나뉘어 들어가게 된다. 이런 전역 변수와 정적 변수의 특징은 프로그램이 실행될 때부터 종료될 때까지 메모리에 남아서 살아 있다는 점이다. 그렇다면 어떤 변수들이 Data 영역으로 들어가고 BSS 영역으로 들어가는 것일까?
Data 영역
전역이나 정적 변수들 중에서 초기화가 된 변수들은 모두 Data 영역으로 들어가게 된다.
BSS 영역
전역이나 정적 변수들 중에서 초기화가 되지 않은 변수들에 대해서는 BSS 영역에 들어가게 된다. (BSS라는 말은 Block Started by Symbol을 말한다.)
정리
int newInt = 1; // newInt는 Data 영역
double newDouble = 1.0; // newDouble도 Data 영역
int toBSS; // BSS 영역
int uninitializedInt; // BSS 영역
C
복사
위 코드에서 보는 것과 같이 먼저 제시된 두 케이스의 변수는 Data 영역에 저장되며, 아래 두 케이스는 BSS 영역에 할당된다. Data 영역과 BSS 영역은 다음과 같이 동작한다.
실행 파일을 구동하자마자 main함수가 호출되기 이전에, 초기화 된 전역 변수 혹은 정적 변수들에 대해서는 Data 영역에 할당하고 초기화가 되지 않은 전역 변수 혹은 정적 변수들은 BSS 영역에 할당하게 된다. 그리고 BSS 영역에 담긴 변수들에 대해서는 그 값을 0으로 초기화하여 이용하게 된다.
즉, BSS 영역으로 따로 분류해둔 덕에 전역 변수나 정적 변수들은 그 초기 값이 쉽게 0이 될 수 있었던 것이다.
4. 주소 값 확인을 통한 Memory Layout 추측
#include <stdio.h>
int initializedGlobalVariable = 0;
int uninitializedGlobalVariable;
int main()
{
char *strPointer = "First String";
char stringArray[100] = "Second String";
const char stringContant[100] = "Constant String";
static int initializedInt = 1;
static int uninitializedInt;
printf("%p\n", main);
printf("%p\n", "HELLO");
printf("%p\n", strPointer);
printf("%p\n", &initializedGlobalVariable);
printf("%p\n", &initializedInt);
printf("%p\n", &uninitializedGlobalVariable);
printf("%p\n", &uninitializedInt);
printf("%p\n", &strPointer);
printf("%p\n", stringArray);
printf("%p\n", stringContant);
return 0;
}
C
복사
위와 같은 코드가 있다고 해보자. 지금까지 설명한 구조에 따라서 나눠서 낮은 주소 값을 가진 것부터 예측을 해보자.
1) 컴파일 타임
•
우선 사용된 함수는 오로지 main 함수 한 개이고, 코드 내에 사용된 함수들은 코드 전체 내용을 포함하여 Text 영역에 생성되어 가장 먼저 메모리에 할당된다.
•
코드들을 Text 영역에 할당 했기 때문에 Init 영역과 RO Data 영역에 리터럴들을 할당하게 된다. printf문에 사용된 "Hello"의 경우 RO Data 영역에 생성된다. 그 이후, "First String", "Second String", "Constant String"과 같은 문자열 리터럴을 포함하여 0, 1과 같은 정수 리터럴들은 모두 초기화에 이용된 리터럴들이기 때문에 Init 영역에 존재하게 된다.
•
Global에 선언된 unitializedGlobalVariable과 main문에 존재하는 static 키워드가 붙은 uninitializedInt는 초기화 되지 않은 변수들이기 때문에 BSS 영역에 존재하게 된다.
•
Global에 선언된 initializedGlobalVariable과 main문에 존재하는 static 키워드가 붙은 initializedInt는 초기화가 된 변수들이기 때문에 Data 영역에 존재하게 된다.
2) 런 타임, main 함수 호출 전
•
BSS 영역에 존재하는 변수들에 대해서 0을 할당
•
Data 영역에 존재하는 변수들에 대해서 Init 영역을 확인하여 값을 할당
3) 런 타임
•
Stack에 strPointer라는 포인터 변수 할당, stringArray 배열 할당, const가 붙은 stringConstant 배열 할당 (이 때, 각 변수와 배열에 할당되는 값들은 Init 영역에서 찾아 그 값을 할당하게 된다.)
4) 결과 및 결론
따라서 위 코드의 결과로 메모리 주소를 찍어보면 아래와 같은 결과를 얻을 수 있다.
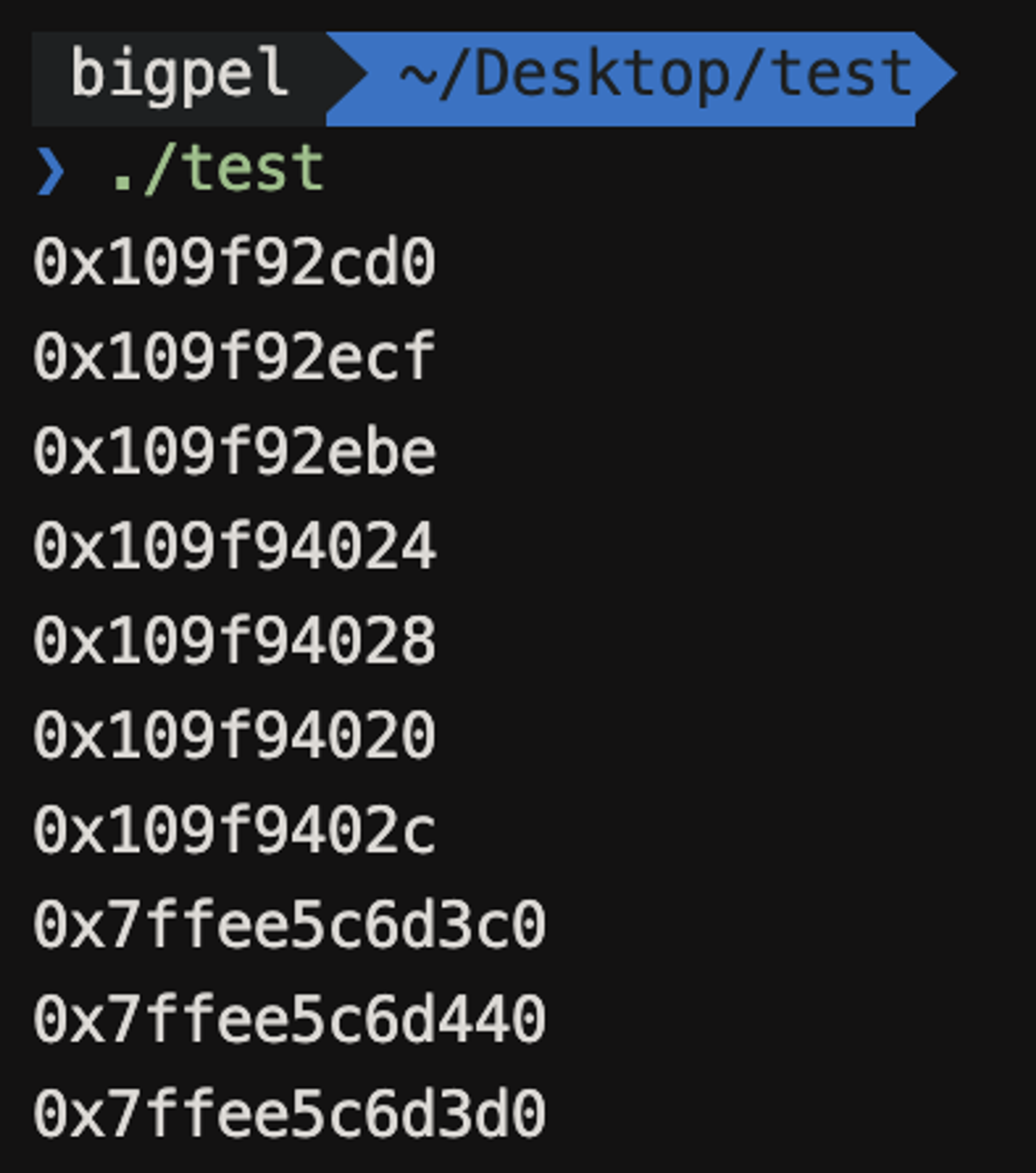
main 함수가 가장 낮은 메모리에 존재하는 것이 맞고, 그 보다 조금 높은 곳에 위치한 것이 RO Data 영역에 있는 Hello라는 문자열 리터럴임을 알 수 있다. 그리고 "First String"과 같이 초기화에 사용된 문자열 리터럴이 RO Data 영역보다 조금 더 높은 Init 영역에 위치한 것을 볼 수 있고, BSS 영역에 위치한 초기화 되지 않은 전역 및 정적 변수가 Init 영역보다 높은 곳에 위치한 것을 볼 수 있다. 이어서 Data 영역에 존재하는 초기화 된 변수들이 위치하는 것을 볼 수 있고, Stack에 존재하는 strPointer 변수, stringArray와 stringConstant 배열이 선언된 순서대로 높은 주소 값에서부터 나타나는 것을 볼 수 있다.