


1. V8 엔진과 libuv 라이브러리 그리고 코드의 실행 플로우
Node.js는 우리가 작성한 JavaScript 코드에 대해서 브라우저 이외의 환경에서 실행할 수 있도록 런 타임을 제공한다. 이런 Node.js는 V8 엔진과 libuv 라이브러리라는 2가지 Dependency를 갖고 있다.
우리가 JavaScript 코드를 작성하면 이는 100% JavaScript로 구성된 코드이지만, 실제로 Node.js는 약 50%의 JavaScript와 50%의 C++로 구성된다. 이런 구성을 보이는 이유는 V8 엔진이 약 30%의 JavaScript와 70%의 C++로 구성되고, libuv는 순수히 100%의 C++로 구성되어 있기 때문이다.
V8 엔진은 JavaScript 코드에 대한 실행 및 JavaScript 코드를 Byte Code로 만들어 C++에게 이해시키는 역할을 담당한다. 반면 libuv는 파일 시스템이나 네트워크 작업과 같은 비동기 작업을 처리하는 역할을 담당한다. 제시된 2가지를 이용하여 우리는 JavaScript로 코드를 작성하더라도 직접적으로 C++을 건드리는 일 없이, C++로 작성된 훌륭한 코드들을 이용할 수 있고 Node.js는 이런 훌륭한 인터페이스를 제공하는 역할을 하게 되는 것이다.
그렇다면 Node.js의 Standard Library Module 중에 하나를 골라서 실제 코드로는 어떻게 구현이 되어 있는지 확인해보고, 이걸 구현하는데 있어서 V8 엔진과 libuv가 어떻게 적용되었으며 실제로 코드를 실행하면 어떤 플로우로 실행이 되는지 알아보자.
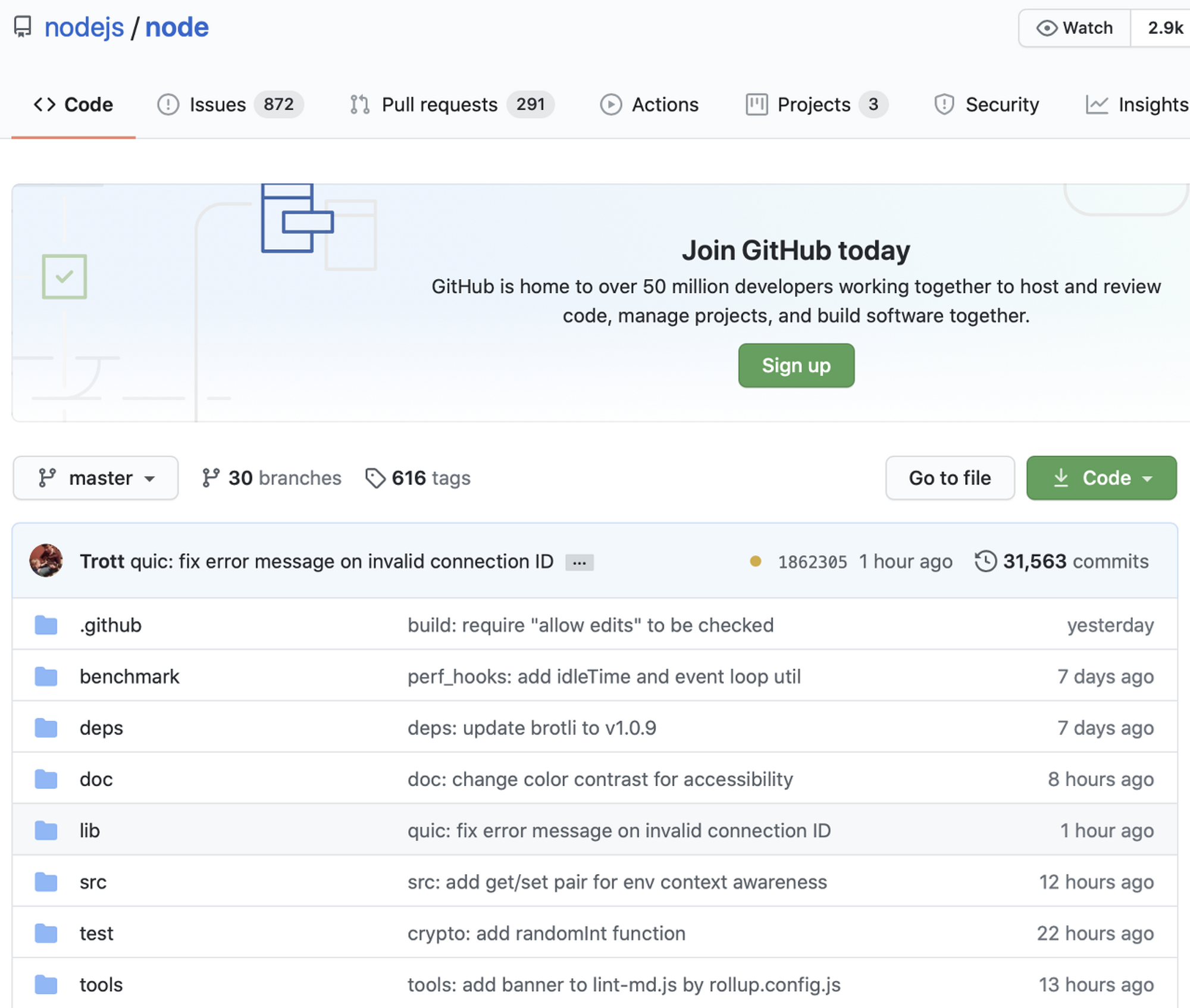
위 사진은 실제 Node.js의 소스 코드들이다. 우리가 JavaScript 코드를 작성하면서 사용하는 Standard Library 함수들은 lib라는 디렉토리에 존재하고, 해당 라이브러리 함수들의 실질적인 기능이 C++로 작성되어 있는 곳은 src 디렉토리에 존재한다.
node/lib/internal의 경로를 탐색을 해보면, Node.js에서 제공하는 console, crypto, fs util 등 익숙한 라이브러리들을 확인할 수 있다. 이 중에서 crypto 라이브러리의 pbkdf2라는 단방향 암호화 해쉬 함수를 살펴보고 해당 함수의 JavaScript의 실행 과정을 알아보겠다.
function pbkdf2(password, salt, iterations, keylen, digest, callback) {
if (typeof digest === 'function') {
callback = digest;
digest = undefined;
}
if (typeof callback !== 'function')
throw new errors.TypeError('ERR_INVALID_CALLBACK');
return _pbkdf2(password, salt, iterations, keylen, digest, callback);
}
JavaScript
복사
function _pbkdf2(password, salt, iterations, keylen, digest, callback) {
if (digest !== null && typeof digest !== 'string')
throw new errors.TypeError('ERR_INVALID_ARG_TYPE', 'digest', [
'string',
'null',
]);
password = toBuf(password);
salt = toBuf(salt);
if (!isArrayBufferView(password)) {
throw new errors.TypeError('ERR_INVALID_ARG_TYPE', 'password', [
'string',
'Buffer',
'TypedArray',
]);
}
if (!isArrayBufferView(salt)) {
throw new errors.TypeError('ERR_INVALID_ARG_TYPE', 'salt', [
'string',
'Buffer',
'TypedArray',
]);
}
if (typeof iterations !== 'number') {
throw new errors.TypeError(
'ERR_INVALID_ARG_TYPE',
'iterations',
'number'
);
}
if (iterations < 0) {
throw new errors.RangeError(
'ERR_OUT_OF_RANGE',
'iterations',
'a non-negative number',
iterations
);
}
if (typeof keylen !== 'number') {
throw new errors.TypeError('ERR_INVALID_ARG_TYPE', 'keylen', 'number');
}
if (keylen < 0 || !Number.isFinite(keylen) || keylen > INT_MAX) {
throw new errors.RangeError('ERR_OUT_OF_RANGE', 'keylen');
}
const encoding = getDefaultEncoding();
if (encoding === 'buffer') {
const ret = PBKDF2(
password,
salt,
iterations,
keylen,
digest,
callback
);
if (ret === -1)
throw new errors.TypeError('ERR_CRYPTO_INVALID_DIGEST', 'digest');
return ret;
}
if (callback) {
function next(er, ret) {
if (ret) ret = ret.toString(encoding);
callback(er, ret);
}
if (PBKDF2(password, salt, iterations, keylen, digest, next) === -1)
throw new errors.TypeError('ERR_CRYPTO_INVALID_DIGEST', digest);
} else {
const ret = PBKDF2(password, salt, iterations, keylen, digest);
if (ret === -1)
throw new errors.TypeError('ERR_CRYPTO_INVALID_DIGEST', digest);
return ret.toString(encoding);
}
}
JavaScript
복사
const { PBKDF2 } = process.binding('crypto');
JavaScript
복사
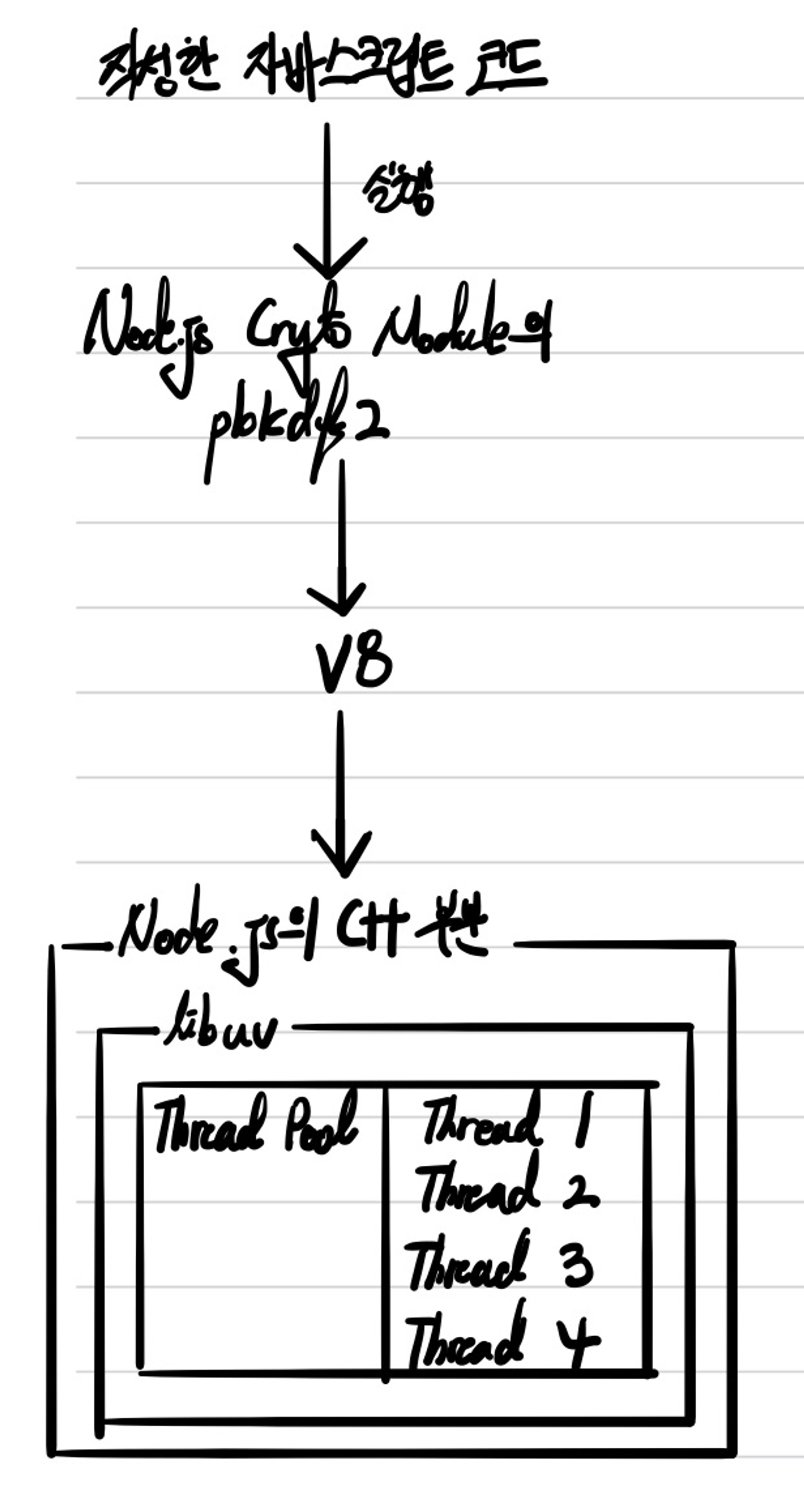
위의 첫번째 코드가 바로 node/lib/internal/crypto/pbkdf2.js의 pbkdf2 함수이다. 실제로 pbkdf2 함수를 호출했을 때 실행되는 코드들이고, digest와 callback과 같은 간단한 에러 검출만 되면 Underscore가 붙은 내부 함수인 _pbkdf2를 호출하는 것을 볼 수 있다.
_pbkdf2를 호출하게 되면 내부적으로 해당 함수의 기능과 관련된 함수 인자들에 대해서 추가적으로 에러 검출을 해보고, 아무런 문제가 없으면 All Capital로 된 PBKDF2라는 함수를 호출하게 된다.
All Capital 함수인 PBKDF2라는 함수는 process.binding을 통해서 JavaScript에서의 PBKDF2라는 이름과 C++에서의 PBKDF2와 연결되어 있어서, 해당 함수를 호출하면 C++에서의 함수가 호출되면서 작업을 수행한다.
여기까지가 pbkdf2를 JavaScript로 코드를 작성했을 때 실행되는 부분들이고, src에 있는 아래 코드들을 통해서 C++ 부분이 어떻게 실행이 되는지 알 수 있다.
node/src/node_crypto를 살펴보면 위 함수가 작성된 버전을 기준으로 약 5000라인이 존재한다.
env->SetMethod(target, "PBKDF2", PBKDF2);
C++
복사
void PBKDF2(const FunctionCallbackInfo<Value> &args) {
// PBKDF2 Function Implementation
}
C++
복사
위와 같이 process.binding은 setMethod 함수를 통해 JavaScript와 C++의 함수가 연결된 것을 볼 수 있고, 실제 기능을 하는 C++ 함수가 존재하는 것을 볼 수 있다. 그리고 JavaScript의 함수가 C++과 연결 되면서 실제 기능 수행은 C++로 하게 되지만, C++의 함수에 필요한 인자들은 JavaScript 함수로부터 받게 된다. JavaScript의 데이터 타입과 C++에서의 데이터 타입이 다르기 때문에, 함수 인자의 데이터 타입 변환이 필요하고 이 작업을 V8 엔진이 수행하게 된다.
node/src/node_crypto.cc의 상단에 보면 아래와 같은 코드가 있는데, 여러 using 구문들을 통해 JavaScript 내부의 타입을 C++의 것과 동일하게 바꾸게 되는 것이다.
using v8::Array;
using v8::ArrayBufferView;
using v8::Boolean;
using v8::ConstructorBehavior;
using v8::Context;
using v8::DontDelete;
using v8::Exception;
using v8::External;
using v8::False;
using v8::Function;
using v8::FunctionCallback;
using v8::FunctionCallbackInfo;
using v8::FunctionTemplate;
using v8::HandleScope;
using v8::Int32;
using v8::Integer;
using v8::Isolate;
using v8::Just;
using v8::Local;
using v8::Maybe;
using v8::MaybeLocal;
using v8::NewStringType;
using v8::Nothing;
using v8::Null;
using v8::Object;
using v8::PropertyAttribute;
using v8::ReadOnly;
using v8::SideEffectType;
using v8::Signature;
using v8::String;
using v8::Uint32;
using v8::Undefined;
using v8::Value;
C++
복사
여기까지의 과정을 다시 한 번 깔끔한 플로우로 정리하면 다음과 같다.
1. JavaScript 코드를 작성하고 코드를 실행하면서 Standard Library Module의 함수를 호출한다.
2. Node.js의 JavaScript 부분에 해당하는 lib에서 해당 함수를 찾는다.
3. 해당 함수가 수행되면서 함수의 기능과 크게 직결되지 않은 인자에 대해서 에러 검출을 수행한다.
4. Underscore가 붙은 내부 함수에서 함수의 기능과 직결된 인자에 대해서 에러 검출을 수행한다.
5. process.binding을 통해서 JavaScript의 함수와 연결된 C++의 원 함수를 호출하게 된다. (process.binding을 하게 되면 src에서 해당 함수에 매칭되는 스크립트에서 env->SetMethod를 통해서 연결이 된다.)
6. 호출하는 과정에서 넘겨받은 인자들은 src의 스크립트에서 using 구문을 통해 v8 객체에 존재하는 객체들로 타입을 이용할 수 있게 되고, C++의 원 함수를 수행할 때는 JavaScript에서 넘겨받은 함수 인자라고 하더라도 정상적으로 C++에서 이용할 수 있게 된다.
7. 5에서 원 함수를 호출 했기 때문에 호출한 함수를 src에서 찾게 된다.
8. libuv가 함수에대해서 적절히 처리하게 된다. (파일 시스템과 같은 Long Operation들은 Thread Pool로, 네트워크와 같은 OS Task들은 운영체제로 넘기면서 처리하도록 만든다.) pbkdf2의 경우는 uv_thread_t 객체를 이용하여 Thread Pool로 넘기면서 작업을 처리하게 된다.
위 설명은 꽤 이전 버전에서의 Node이다. 이 때는 Underscore가 붙은 _pbkdf2라는 함수도 동일 디렉토리 안에 정의되어 있었고, binding도 process.binding으로 되어 있어서 찾기 쉬웠다.
현재는 내부적으로 binding이 되어 있어서 _pbkdf2라는 함수도 쉽게 찾을 수 없고 process.binding이 아닌 internalBinding으로 바뀌면서 사용자가 쉽게 바꿀 수 없게 만들어 두었다.
이에 대해서는 링크의 Internals of Node - Advance Node의 C++ binding Loaders를 참고하면, process.binding, process._linkedBinding, internalBinding에 대해서 확인할 수 있다.
2. Event Loop의 반복 조건 및 반복 내용
Event Loop의 Single Thread 처리를 작성하기 이전에, Thread에 대해서 먼저 정리해보고자 한다.
프로그램이 실행되어 있는 것을 프로세스라고 하는데, CPU가 프로세스를 처리하는 기본 단위는 Thread이다. 그리고 프로세스는 1개의 Thread일 수도, 여러 개의 Thread로 나뉠 수도 있다. 이는 프로세스에 대해서 Multi-Threading을 지원한다면 1개의 프로세스를 여러 작업으로 나누어 처리할 수 있음을 의미한다.
(프로세스의 Thread는 OS의 스케줄러에 의해서 실행 순서가 결정되고, 자신의 실행 순서가 되면 Thread는 Task의 Instruction들을 CPU에 넘기면서 연산을 수행하게 된다. Thread를 실행하여 처리할 때 좋은 성능을 내기 위해선 Multi-Core Multi-Thread를 지원하는 머신 레벨의 향상을 만들거나, 좋은 스케줄러를 사용하면 된다. 여기서의 좋은 스케줄러는 스케줄링을 잘하는 것을 의미할테고, 이는 곧 어떤 Task들이 오래 걸릴지 잘 파악할 수 있고 이에 맞춰 Thread를 할당하여 순서를 맞추는 것을 의미한다. 좋은 스케줄링은 Thread의 Task에 대해서 정확한 Detection을 수행할 때 이뤄질 수 있는 것이다.)
Node.js의 Event Loop는 Single Thread로 JavaScript 코드를 처리한다. 즉, 여러 Thread로 나뉘어서 코드들을 수행하는 것이 아니라 오로지 1개의 Thread만 코드 처리에 이용되는 것이다.
1) 반복 조건
Event Loop는 말 그대로 Loop 이기 때문에 1회 반복 (1 Tick)을 하면서 수행하는 내용들과 반복을 위한 조건이 존재한다. 반복 조건은 3가지 요소로 나뉜다.
pendingTimers
setTimeout, setInterval, setImmediate과 같은 Timer 함수
pendingOSTasks
네트워크 (HTTP, HTTPS Request 혹은 Server의 Port Listening과 같은) 작업들
pendingOperations
파일 시스템과 같이 Long Running이 필요한 작업들
이렇게 3가지 요소 중 하나라도 존재한다면 Event Loop는 종료되지 않고 프로그램은 끝나지 않은 상태로 유지된다. 그렇다면 Event Loop은 1 Tick마다 어떤 작업을 수행하게 되는지 알아보자.
2) 반복 내용
처리하는 내용은 아래와 같다.
1.
pendingTimers에 대해서 작업을 처리하는 Callback 함수의 호출 준비가 되었는지 Timer를 확인하게 된다. (setTimeout, setInterval에만 해당하고 setImmediate은 해당하지 않는다.) 확인 후 Callback 함수 호출이 가능하다면 호출한다.
2.
pendingOSTasks와 pendingOperations에 대해서 해당 작업들의 Callback 함수를 호출할 수 있는지 확인하고, 문제가 없다면 Callback함수를 호출하게 된다.
3.
pendingTimers, pendingOSTasks, pendingOperations에 대한 Callback 함수를 수행하는 동안 Event Loop는 잠시 멈추는 Pause 상태가 되었다가 작업들을 모두 마치면 다시 Resume 상태로 작업을 이어나간다. (예측하건대, 각 비동기 작업들이 실행할 때 Call Stack이 빌 때마다 작업을 실행할 수 있게 되므로, 실행해야하는 비동기 작업들이 모두 실행되고 Call Stack이 빌 때까지 기다리는 것 같다.)
4.
pendingTimer에 대해서 setImmediate에 대한 작업을 처리한다. (1에서는 setImmediate을 제외한 작업들만 처리했었다.)
5.
Close 태그의 Event들을 처리한다. (socket.on('close', cb)와 같은 close, destroy Event Callback을 처리한다. 이를 통해 코드를 Cleaning Up할 수 있고 Dangling Loose End 상황을 피할 수 있다.)
Pseudo Code로는 아래와 같이 이뤄진다. 반복 조건과 반복 내용을 비교해가면서 읽어보자.
const pendingTimers = [];
const pendingOSTasks = [];
const pendingOperations = [];
// 프로그램이 실행되면서 새로운 Timers, OS Tasks, Operations들을 기록한다.
jsFileForRun.runContents();
function shouldContinue() {
// 1. Any pending setTimeout, setInterval, setImmediate?
// 2. Any pending OS Tasks like Server Listening to Port?
// 3. Any pending long running operations like FS Module?
return (
pendingTimers.length ||
pendingOSTasks.length ||
pendingOperations.length
);
}
// jsFileForRun은 프로그램이 계속 실행되고 있는 도중에
// Pending 작업들의 수를 계속해서 기록하고 있다.
// Event Loop는 반복문을 돌 때마다
// Pending 작업의 수를 통해 반복 여부를 결정한다.
while (shouldContinue()) {
// 1. pending Timers의 setTimeout, setInterval을 확인하고 처리할 준비가 된 함수들을 처리
// 2. pending OS Tasks와 pending Operations의 Callback 함수 수행 여부를 확인 후 처리
// 3.
// 새로운 pendingOSTask가 다 처리되고,
// 새로운 pendingOperation이 처리되고,
// Timer 관련 작업이 다 처리 될 때까지 기다렸다가 반복을 속행한다.
// 4. pendingTimers의 setImmediate 처리
// 5. Close Event 처리
}
// Exit
JavaScript
복사
3. Node.js는 Singe Thread로 동작하는가?
결론부터 말하면, Node.js의 Event Loop는 Single Thread가 맞지만 Node.js의 몇 Framework와 Standard Library 함수들에 대한 작업은 Single Thread가 아니다. 즉, Node.js의 작동은 오로지 Single Thread 인 것은 아니다.
이에 대해서 pbkdf2 함수를 수행하는 예시를 통해 살펴보자.
const crypto = require('crypto');
const start = Date.now();
crypto.pbkdf2('a', 'b', 200000, 512, 'sha512', () => {
console.log('1번 작업:', Date.now() - start);
});
JavaScript
복사
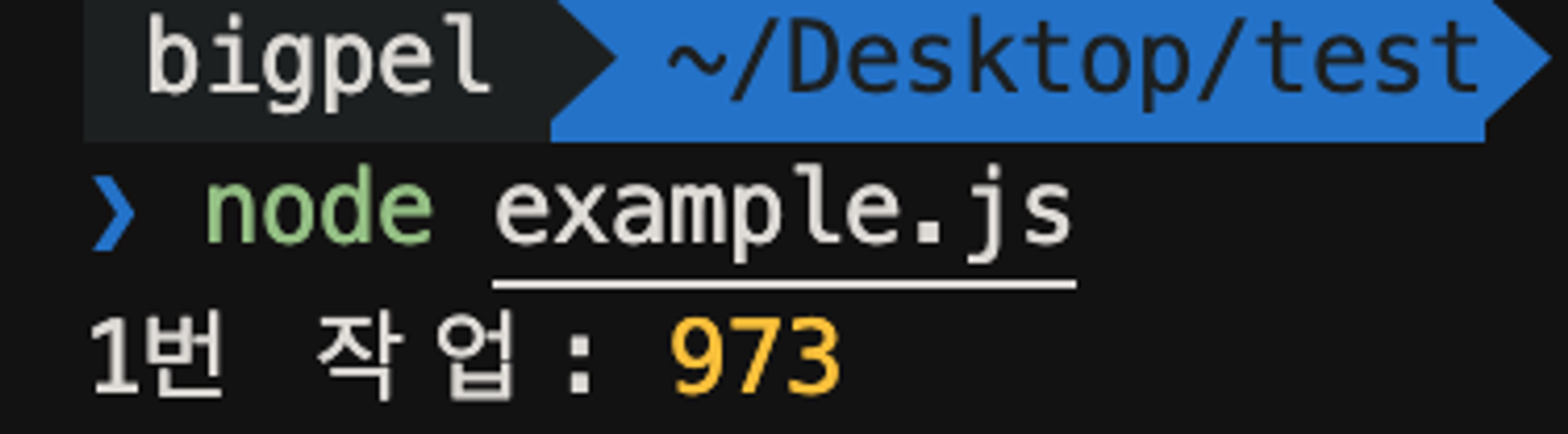
위와 같은 코드가 있고 실행 결과는 약 1000ms, 1초 정도 소요가 됐다고 하자. 위와 같은 작업을 2개를 수행한다고 했을 때, Node.js의 작업이 Single Thread라면 그 실행 결과는 약 2000ms, 2초 정도 소요가 되어야한다. 과연 2개의 pbkdf2 작업을 수행 했을 때 결과는 어떻게 될까?
const crypto = require('crypto');
const start = Date.now();
crypto.pbkdf2('a', 'b', 200000, 512, 'sha512', () => {
console.log('1번 작업:', Date.now() - start);
});
crypto.pbkdf2('a', 'b', 200000, 512, 'sha512', () => {
console.log('2번 작업:', Date.now() - start);
});
JavaScript
복사
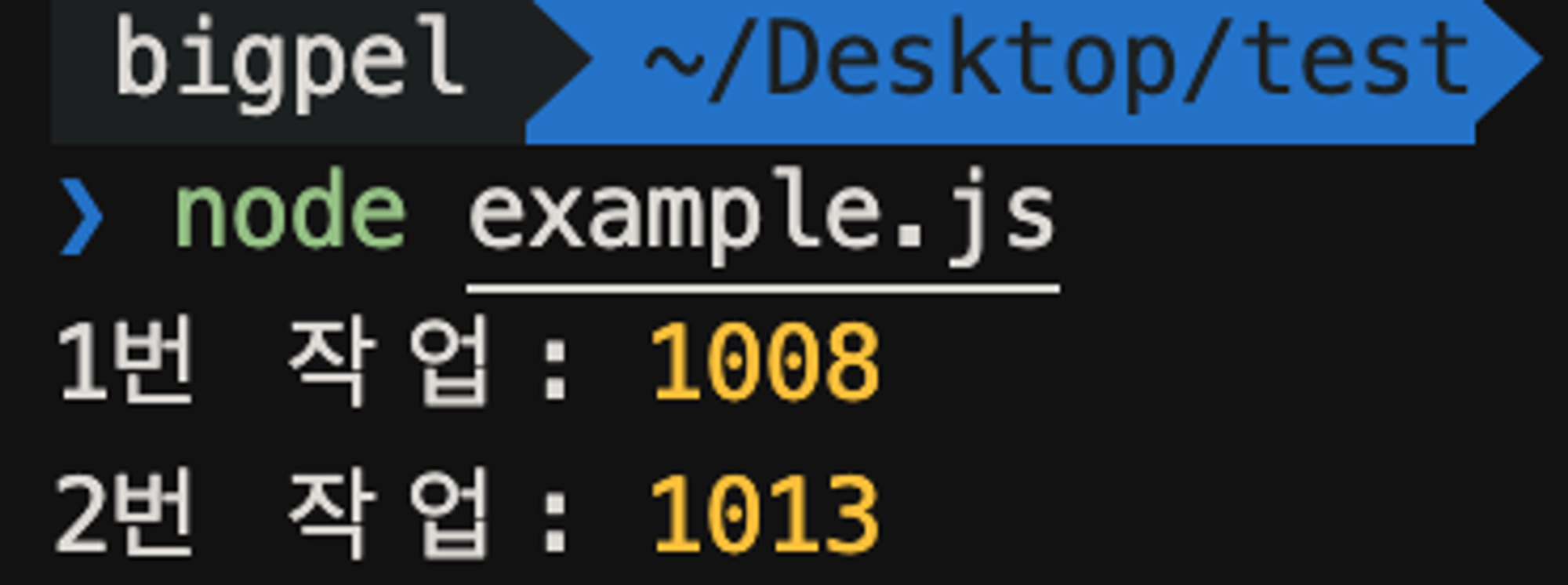
이전보다 조금 느려지긴 했으나, 2개의 작업 모두 1초에 끝났다. 과연 Node.js가 오로지 Single Thread로 동작한다면 가능한 결과일까?
이에 대해서는 실행 환경마다 다를 수 있다. 예를 들어 컴퓨터에서 동작할 수 있는 논리 코어가 1개이고 Thread Pool의 사이즈가 1이라면, Node.js가 오로지 Single Thread로만 작동하지 않는다고 했어도 결과는 다르게 나온다. 1번 작업의 처리 결과 1초, 2번 작업의 처리 결과 2초가 나온다. 또한 논리 코어가 1개이고 Thread Pool의 사이즈가 2라면 1번 작업의 처리 결과와 2번 작업의 처리 결과 모두 2초가 나온다.
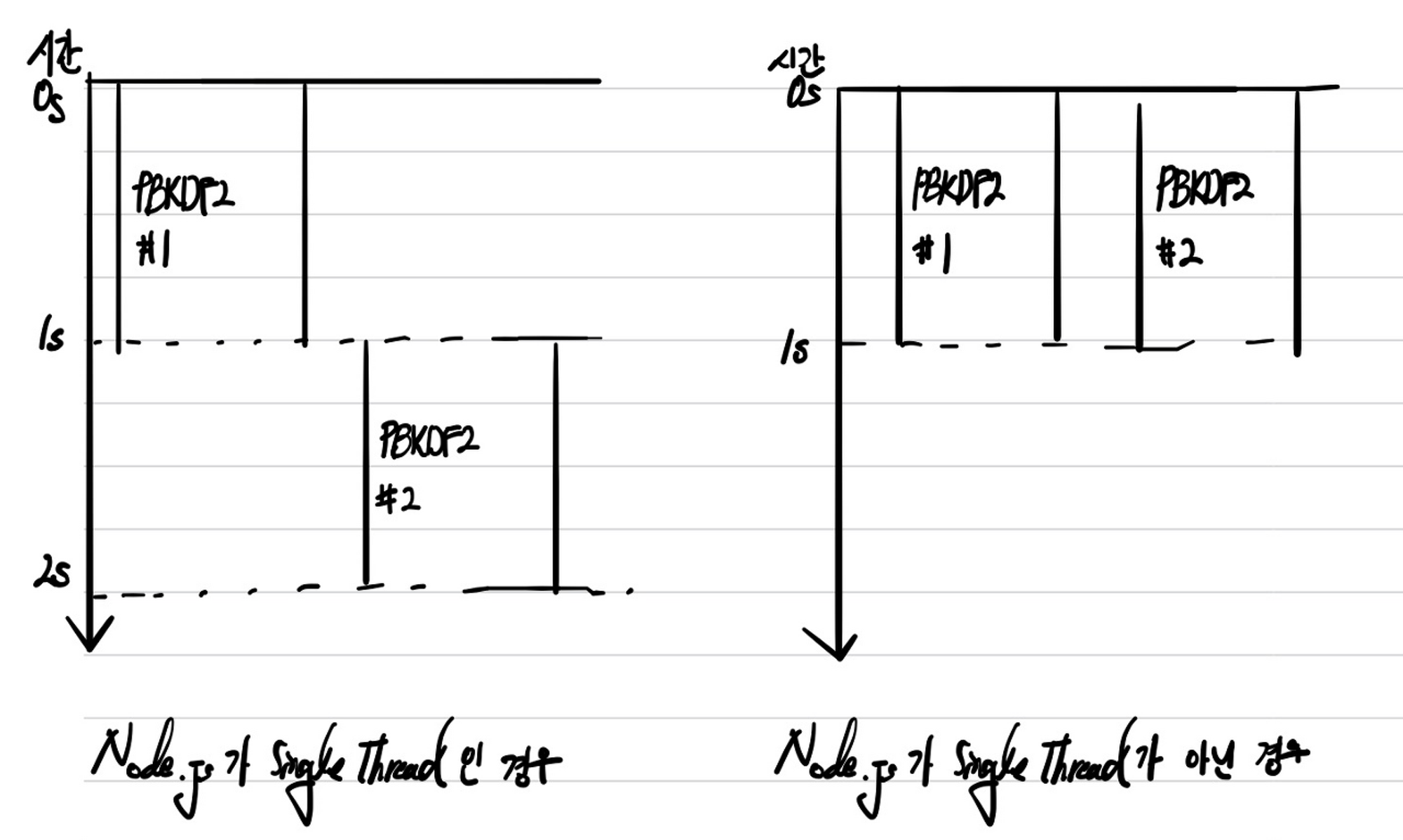
이렇게 Single Thread로 처리되지 않는 것은 Node.js의 libuv의 Thread Pool 덕분이다.
4. libuv의 Thread Pool
libuv의 Thread Pool의 Default Size는 4이다. 즉, uv_thread_t로 동작하는 작업들이 한 번에 최대 4개까지 등록이 가능하다는 것이다. 이 Thread Pool Size는 JavaScript 코드를 작성할 때 아래 구문을 통해 크기 조정이 가능하다.
process.env.UV_THREADPOOL_SIZE = 4
C++
복사
이전의 테스트 코드가 어떤 플로우로 Multi-Threading이 된 것인지 살펴보면 아래와 같다.
2개의 pbkdf2 중에서 1번을 호출하면 Event Loop는 해당 함수를 Call Stack에 넘기면서 해당 함수가 실행된다. pbkdf2 함수의 내부에 있는 All Capital 함수 PBKDF2를 만나는 순간 C++ 부분을 처리하기 위해 libuv의 Thread Pool로 넘기게 되고, Call Stack은 이 작업이 완료될 때까지 기다리는 것이 아니라 그 다음 2번 pbkdf2를 호출한다. 마찬가지로 2번 함수도 Call Stack에서 이를 실행하게 되고, 1번과 마찬가지로 내부의 All Capital 함수 PBKDF2를 만나는 순간 해당 작업도 libuv의 Thread Pool로 넘기게 된다. 따라서 Thread Pool로 넘어간 2개의 작업은 동시에 처리되는 것이다.
위 작업들은 작업이 완료되었을 때 실행되는 Callback의 Chaining으로 작성된 것도 아니고, Promisify를 통해 async await을 해준 것도 아니기 때문에 Call Stack에서 작업을 처리하면서 결과를 받을 때까지 기다리지 않는다. 완료되지 않았음에도 바로 그 다음 라인을 실행하게 되고, 작업 완료 시에 Console에 로그를 남기는 것은 Callback 함수를 통해 이뤄지게 된다. 심지어 이 모든 과정은 굉장히 짧은 시간에 이뤄진다.
Thread Pool의 크기를 18으로 늘리고 pbkdf2 함수를 18개를 실행을 하는 경우에는 모든 작업의 실행 결과가 모두 약 1초가 될까? 결과는 그렇지 않다. 현재 내가 사용하고 있는 컴퓨터의 논리 코어는 16개이고, 이 때 Thread Pool이 18개의 Thread를 한 번에 실행 시킬 수 있음에도 결국에 연산에 사용될 수 있는 코어는 최대 16개까지므로 나머지 2개의 Thread 작업이 완료될 때까지 Thread Pool은 기다리다가 모든 작업들을 한 번에 완료시키게 된다. 따라서 1초가 아닌 그 이상의 시간이 걸리게 된다.
결과적으로 Event Loop는 JavaScript 코드에 대한 처리를 담당하고 Thread Pool은 Standard Library의 파일 시스템이나 Crypto의 일부 기능 중 무거운 작업들에 한하여 동작하게 된다. 즉, libuv를 사용하지 않는 순수한 JavaScript에 대해서는 Event Loop에 의해 Single Thread로 처리가 되고, libuv를 통해서 처리해야 하는 작업의 경우 Multi-Thread로 동작할 수 있기 때문에 Node.js는 엄밀히 Single Thread로 동작하는 것은 아니다.
이렇게 Thread Pool을 이용해야 하는 작업들은 Event Loop의 반복 조건 중에 pendingOperations에 해당한다.
5. libuv의 OS Delegation
작성한 JavaScript를 Node.js를 통해 실행하여 C++로 처리하게 되면 모두 다 Thread Pool을 통해서 실행하게 되는 것일까? 제일 처음 항목의 JavaScript 코드 실행 플로우를 보면 libuv를 사용하는 부분에서 Long Operations는 Thread Pool을 이용하지만, OS Tasks는 Thread Pool을 사용하는 것이 아니라 운영체제의 도움을 받는다고 하였다. pendingOSTasks는 무엇이고, Thread Pool을 정말 이용하지 않는지 확인해보자.
const https = require('https');
const start = Date.now();
function doRequest() {
https
.request('https://www.google.com', (res) => {
res.on('data', () => {});
res.on('end', () => {
console.log(Date.now() - start);
});
})
.end();
}
JavaScript
복사
다음과 같은 HTTPS 요청 함수가 있다고 하자. libuv의 Thread Pool에서 Thread Pool의 크기를 18, 함수 수행 개수를 18개로 돌리면 한 번에 모두 다 처리가 되지 않는 것을 확인할 수 있었다. 위와 같은 HTTPS 함수도 만일 Thread Pool을 이용한다면, Thread Pool의 크기가 18일 때 해당 함수를 18개로 실행을 한다면 한 번에 다 처리가 되지 않아야 할 것이다.
하지만 위와 같은 네트워크 요청들은 Thread Pool과 CPU 수와 상관 없이 한 번에 처리되는 것을 볼 수 있다. 이는 곧 Thread Pool을 이용하지 않는다는 것을 볼 수 있다.
이런 네트워크 요청들은 Thread Pool에서의 플로우 중에 V8 엔진을 거치고 난 뒤, libuv는 이 작업을 운영체제에 그냥 위임해버린다. 운영체제는 Thread를 만들어서 처리할지 말지 결정한 후, Thread를 만들어서 처리하는 것이 아닌 요청에 대해서는 운영체제가 자체적으로 전반적인 처리 과정을 만들어내게 된다. (이 때 libuv는 운영체제가 네트워크에 대한 요청을 처리하면서 네트워크의 응답을 받았다는 시그널을 나타내기 전까지 대기하게 된다.)
그리고 libuv가 작업을 운영체제에 위임을 하고 나면 그 작업은 오로지 운영체제가 알아서 처리할 일이기 때문에 Event Loop는 비어있는 상태가 되고 계속해서 JavaScript를 처리하면서 운영체제에 작업을 계속 넘기게 된다. 따라서 몇 개의 네트워크 작업에 대해서 요청을 하든, 이 작업들은 작업을 만들어낸 Machine에 대해 Independent한 속성을 갖고 오로지 운영체제와 이를 처리하는 다른 Machine의 능력에 따라 처리가 된다.
위의 테스트의 결과로는 거의 동시에 처리 된다고 볼 수 있다. 이런 네트워크 작업은 Event Loop 반복 조건 중에 pendingOSTasks에 해당한다.
개인적으로 파일 시스템 작업에 해당하는 pendingOperations를 pendingOSTasks로 많이 헷갈렸었다. 네트워크의 요청의 경우 Machine에서 최종 목적지는 OS이고, 파일 시스템의 요청의 경우 Thread Pool의 최종 목적지는 CPU의 연산 작업으로 이해하면서 각각 pendingOSTasks, pendingOperations라고 자연스레 이해하게 되었다.
6. Mind Boggling Behavior
libuv의 Thread Pool을 이용하는 작업과 OS Delegation을 이용하는 작업에 대해서 알아봤다. 그렇다면 한 번 쯤은 부딪힐 수 있는 문제에 대해서 생각을 해보자.
논리 코어는 2개이고, Thread Pool의 크기는 4라고 가정한다. 이 때 아래 코드의 실행 결과는 어떻게 될까? (단, 각 요청을 단일로 처리했을 때 네트워크 요청의 경우 약 200ms, 파일 시스템 요청의 겅우 30ms, 해쉬 함수 수행의 경우 1000ms가 걸린다고 가정한다.)
process.env.UV_THREADPOOL_SIZE = 4;
const https = require('https');
const crypto = require('crypto');
const fs = require('fs');
const start = Date.now();
function doRequest() {
https
.request('https://www.google.com', (res) => {
res.on('data', () => {});
res.on('end', () => {
console.log(Date.now() - start);
});
})
.end();
}
function doHash() {
crypto.pbkdf2('a', 'b', 200000, 512, 'sha512', () => {
console.log('Hash:', Date.now() - start);
});
}
doRequest();
fs.readFile('multitask.js', 'utf8', () => {
console.log('FS:', Date.now() - start);
});
doHash();
doHash();
doHash();
doHash();
JavaScript
복사
나는 처음에 파일 시스템의 결과가 먼저 나오고, 네트워크 요청에 대한 결과가 나온 뒤, 해쉬 함수에 대해서 모두 2000ms들이 나온다고 생각했다.
하지만 위와 같은 환경에서의 답은 네트워크 요청 → 해쉬 1개의 결과 (약 2000ms) → 파일 시스템의 결과 (약 2000ms) → 나머지 해쉬 3개의 결과 (약 2000ms)로 고정 결과가 나온다.
이해가 잘 되지 않았다. 이는 Node.js가 파일 시스템에서 Read 작업을 어떻게 수행하는지를 이해하면 조금 더 쉽게 받아들일 수 있는데, 파일 시스템의 Read 작업은 다음과 같이 일어난다.
1.
fs.readFile을 호출한다.
2.
하드 드라이브에 접근하여 읽으려는 파일의 메타 데이터 (statistics)를 취득한다.
3.
취득한 파일의 메타 데이터를 리턴 받는다.
4.
다시 하드 드라이브에 해당 파일의 Read 요청을 보낸다.
5.
하드 드라이브에 접근하여 읽으려는 파일을 취득한다.
6.
해당 파일을 return 받는다.
이와 같은 과정을 염두에 두고 아래 흐름을 순서대로 따라가보자.

사진에서 나타난 것 중에 2번에서 첫 번째 Thread를 해제하는 특이한 것을 볼 수 있는데 이에 대해서 설명하겠다.
pbkdf2 함수의 실행 목적지는 CPU지만, fs의 Read 작업의 목적지는 하드 드라이브이다. Read 요청을 담은 Thread가 하드 드라이브에 도착하고 나면, Thread에 담긴 요청을 하드 드라이브에 넘김과 동시에 Thread는 Thread가 갖고 있는 Task가 바로 처리되지 않는 것을 인지한다. 즉, Thread는 Thread가 갖고 있던 Task가 하드 드라이브로부터 특정 정보를 받기 전까지 계속 기다려야 하는 것을 알고서 기존 Task를 신경쓰지 않게 되고 새로운 Task를 받을 수 있는 상태로 바뀌어 버린다. 따라서 마지막 pbkdf2 작업이 첫 번째 Thread에 할당되게 된다. 그렇게 첫 번째 Thread는 기존 파일 시스템의 Read 요청을 잊은 채로 pbkdf2의 연산을 수행하게 된다.
그러다가 가장 오랫동안 연산한 두 번째 Thread의 Task가 마치게 되면 두 번째 Thread는 새로운 Task를 받을 수 있는 상태가 되어버리고, 파일 시스템의 Read 작업은 못다한 작업을 두 번째 Thread에서 이어하게 된다.
그 이후는 생각하는 그대로 스무스하게 작업이 진행된다. (Thread가 모자란 상태도 아니기 때문이다.) 따라서 파일 시스템의 작업이 단일로써는 30ms라는 가장 빠른 시간에 끝남에도 불구하고, 위와 같은 상황에서는 Node.js에서의 파일 시스템 Read 동작 방식 때문에 꽤 오랜 시간이 걸리는 것이고, Thread가 빌 때까지 기다리기 때문에 pbkdf2의 작업이 하나라도 완료가 된 다음 쫒기듯이 바로 Read 작업이 완료되는 것이다.
만일 이 문제에서 Thread Pool의 크기가 4에서 5로 증가시켜 작업을 하게 되면 모든 Thread가 Task를 품을 수 있게 되고 파일 시스템은 Thread가 빌 때까지 기다릴 필요가 없기 때문에, 이 때는 파일 시스템 결과 → 네트워크 결과 → 나머지 해쉬 함수 4개의 결과의 순서대로 나오는 것을 볼 수 있게 된다.
7. 느낀 점
개인적으로, 내 생각보다 내용들이 너무 심오해서 처음 듣는 내용이라 그런지 이해하는데 조금 시간이 걸렸던 것 같다. 그럼에도 아직 자세한 Event Loop의 동작 과정을 이해하진 못했다. 글을 올리기 위해 이것 저것 찾아보니 더 자세한 내용들이 많았던 것으로 기억한다. 아직 들어야 할 것들과 볼 것들이 많지만 이번 Node.js 공부를 마치면, 그 다음에는 조금 더 깊게 공부를 해야겠다는 생각이 든다. 한 편으로는 Node.js 의 내부에 대해 엄청 얕게 알고 있었던 것을 느끼고 그만큼 더 배울 수 있어서 좋았다.


